Architecture Patterns
Design a Web Crawler
A web crawler systematically browses the World Wide Web, indexing content by following hyperlinks and storing the data for later retrieval. Effective crawler design requires balancing breadth-first exploration with politeness constraints and efficient storage.
HTTPHTML parsingrobots.txtURL frontierBloom filterBreadth-first searchDepth-first searchRate limitingDistributed processingSpider traps
Practice this topic with AI
Get coached through this concept in a mock interview setting
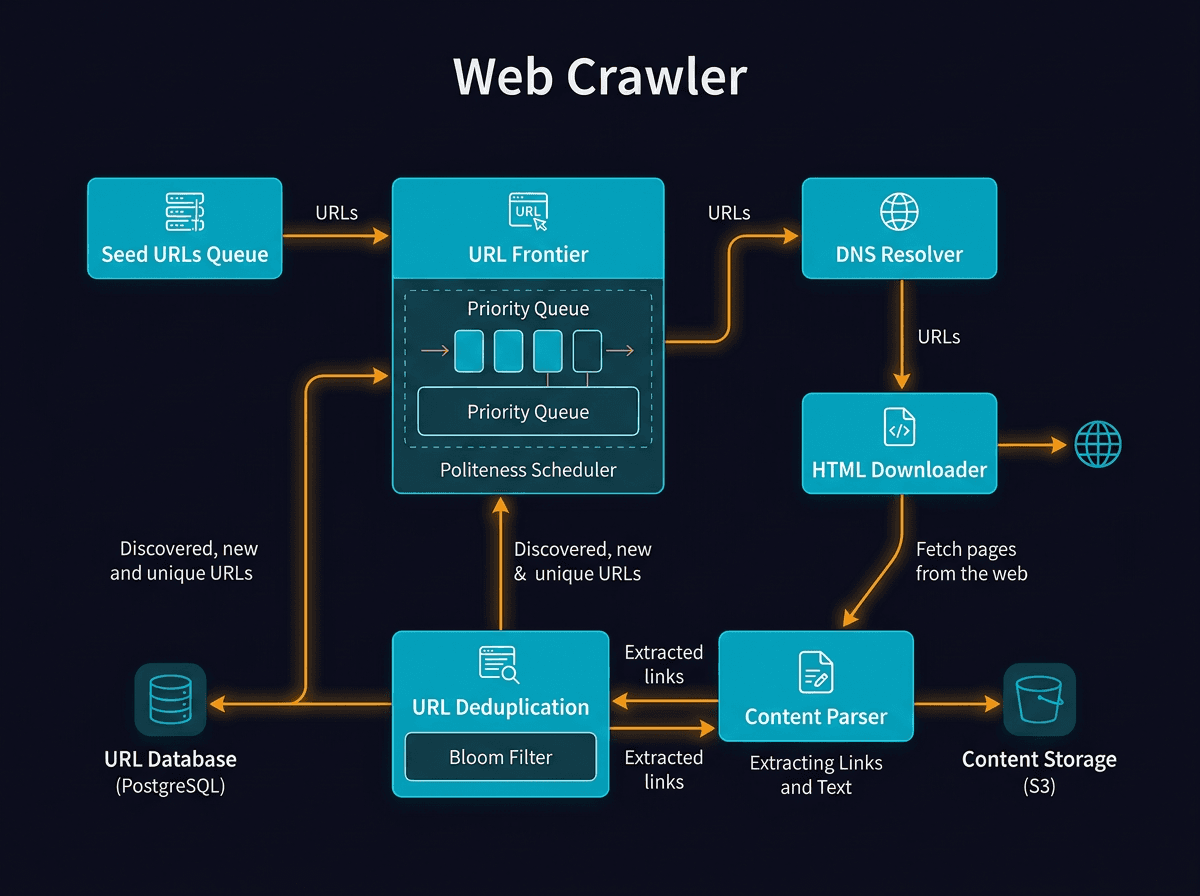
Design a Web Crawler - System Design Diagram
Ready to practice?
Learn step-by-step with diagrams, or get quizzed by an AI interviewer