Design a Distributed Key-Value Store
A distributed key-value store sits at the core of nearly every large-scale system - from DynamoDB to Cassandra to etcd. The design forces you to make hard choices between consistency and availability, pick a partitioning scheme, and build a replication strategy that actually works during network partitions. This walkthrough covers the full design with real tradeoffs, not textbook idealism.
Practice this design with AI
Get coached through each section in a mock interview setting
Problem Statement & Requirements
A distributed key-value store is the most fundamental building block in distributed systems. Every large tech company has built or heavily customized one: Amazon has DynamoDB, Meta has RocksDB/ZippyDB, Apple has FoundationDB. The reason is simple - when you need sub-10ms lookups at millions of QPS, you need something purpose-built.
Functional Requirements
- -Support Put(key, value), Get(key), and Delete(key) operations
- -Keys are strings (max 256 bytes), values are opaque blobs (max 1MB)
- -Support TTL (time-to-live) per key for automatic expiration
- -Provide tunable consistency: clients choose per-request whether they want strong or eventual consistency
- -Support adding/removing nodes with zero downtime
Non-Functional Requirements
- -Throughput: 100K read QPS, 20K write QPS at peak
- -Latency: p99 < 10ms for reads, p99 < 50ms for writes
- -Availability: 99.99% (52 minutes of downtime per year max)
- -Storage: 10TB initially, growing ~1TB/month
- -Durability: zero data loss for acknowledged writes
Out of Scope
- -Range queries and secondary indexes - this is a pure key-value store, not a document database
- -Transactions spanning multiple keys
- -Client library design - assume HTTP/gRPC interface
The critical decision upfront: favor availability over strong consistency (AP in CAP terms). Most key-value store use cases (caching, session storage, user profiles) tolerate brief staleness but cannot tolerate downtime. Strong consistency (CP) is the right choice for coordination services like etcd/ZooKeeper, but not here.
Back-of-Envelope Estimation
Start from the throughput requirements and work backward to infrastructure.
QPS
- -100K read QPS + 20K write QPS = 120K total QPS
- -A single storage node (SSD-backed, well-tuned RocksDB) handles ~50K reads/sec and ~10K writes/sec
- -Minimum nodes for throughput: 3 nodes (with headroom)
- -After replication factor of 3: each write hits 3 nodes, so effective write load = 20K Ã - 3 = 60K writes/sec across the cluster
Storage
- -Average key: 100 bytes. Average value: 1KB. Total per record: ~1.1KB
- -20K writes/sec à - 1.1KB = 22MB/sec ingest rate
- -Daily: 22MB/sec à - 86,400 = ~1.9TB/day
- -But most writes are updates to existing keys, not new keys. Assume 20% are net-new.
- -Net-new storage growth: ~380GB/day = ~11TB/month
- -With replication factor 3: ~33TB/month total disk usage
- -Plan for 6 months of data: ~200TB total cluster storage
Nodes
- -Using 4TB SSD per node: 200TB / 4TB = 50 storage nodes minimum
- -Each node handles ~2.4K reads/sec and ~1.2K writes/sec - well within a single machine's capacity
- -Actual bottleneck at this scale is network, not disk: 50 nodes à - 1Gbps NIC each is plenty
Memory
- -Hot data cache: 20% of keys serve 80% of reads
- -If total unique keys = 10 billion à - 1.1KB = 11TB
- -Cache 20%: ~2.2TB across the cluster = ~44GB per node
- -64GB RAM per node with 44GB for cache leaves headroom for OS and RocksDB block cache
Bottom line: ~50 storage nodes with 64GB RAM and 4TB SSD each. This is a medium-sized cluster - very manageable.
API Design
Keep the API dead simple. A key-value store has three operations. Don't over-design this.
Put a Key
- -PUT
/kv/{key} - -Request:
- -```json
- -
` - -Response (200 OK):
- -```json
- -
`
Get a Key
- -GET
/kv/{key}?consistency=quorum - -Response (200 OK):
- -```json
- -
` - -Response (404):
- -```json
- -
`
Delete a Key
- -DELETE
/kv/{key}?consistency=quorum - -Response: 204 No Content
Design decisions worth calling out
- -The "consistency" parameter is per-request. Clients choose "one" (fastest, eventual), "quorum" (balanced), or "all" (strongest, slowest). This follows Cassandra's model and gives clients control over the latency-consistency tradeoff.
- -Values are base64-encoded to safely transport binary data over JSON. In production, you'd use gRPC with protobuf for better performance.
- -Version numbers enable optimistic concurrency control. A client can do conditional puts: "update only if version == 42." This prevents lost updates without heavyweight locking.
- -No list/scan endpoint. If you need to enumerate keys, you're using the wrong data store. This constraint is intentional - it enables the partitioning strategy to work.
High-Level Architecture
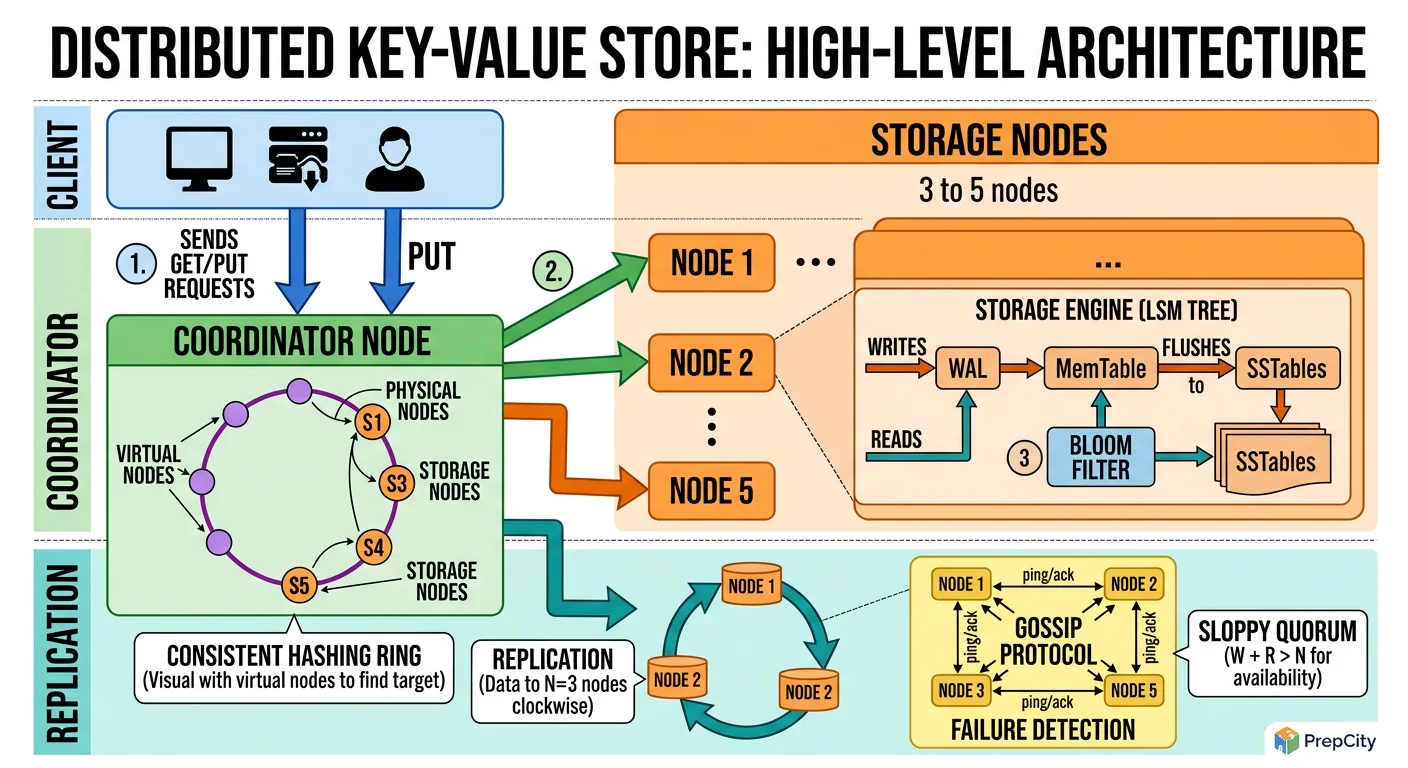
High-Level Architecture
The architecture is a ring of storage nodes with a coordinator layer in front. Every request touches exactly 3 nodes (the replication factor).
Request flow for a write (Put)
1. Client sends PUT to any node. That node becomes the coordinator for this request. 2. Coordinator hashes the key using consistent hashing to find the primary node responsible for this key. 3. Coordinator forwards the write to the primary node and its 2 clockwise neighbors on the ring (replicas). 4. If consistency=quorum, coordinator waits for 2 of 3 nodes to acknowledge. If consistency=one, it returns after the first ack. 5. The remaining replica(s) receive the write asynchronously.
Request flow for a read (Get)
1. Client sends GET to any node (coordinator). 2. Coordinator hashes the key, identifies the 3 responsible nodes. 3. If consistency=quorum, coordinator reads from 2 of 3 nodes and returns the value with the highest version/timestamp. 4. If the 2 reads disagree, coordinator triggers a read-repair: sends the newer value to the stale node.
Core components
- -Consistent Hashing Ring: Maps keys to nodes. Uses virtual nodes (150 vnodes per physical node) for even distribution. Stored in memory on every node and synchronized via gossip protocol.
- -Storage Engine: RocksDB on each node. LSM-tree structure optimized for write-heavy workloads. Write-ahead log (WAL) ensures durability before acknowledging writes.
- -Gossip Protocol: Nodes exchange state every 1 second. Each gossip message contains: node health, ring membership, and schema version. This is how nodes detect failures and ring changes without a centralized coordinator.
- -Anti-Entropy: Background Merkle tree comparison between replicas catches any data divergence that read-repair missed.
Detailed Component Design
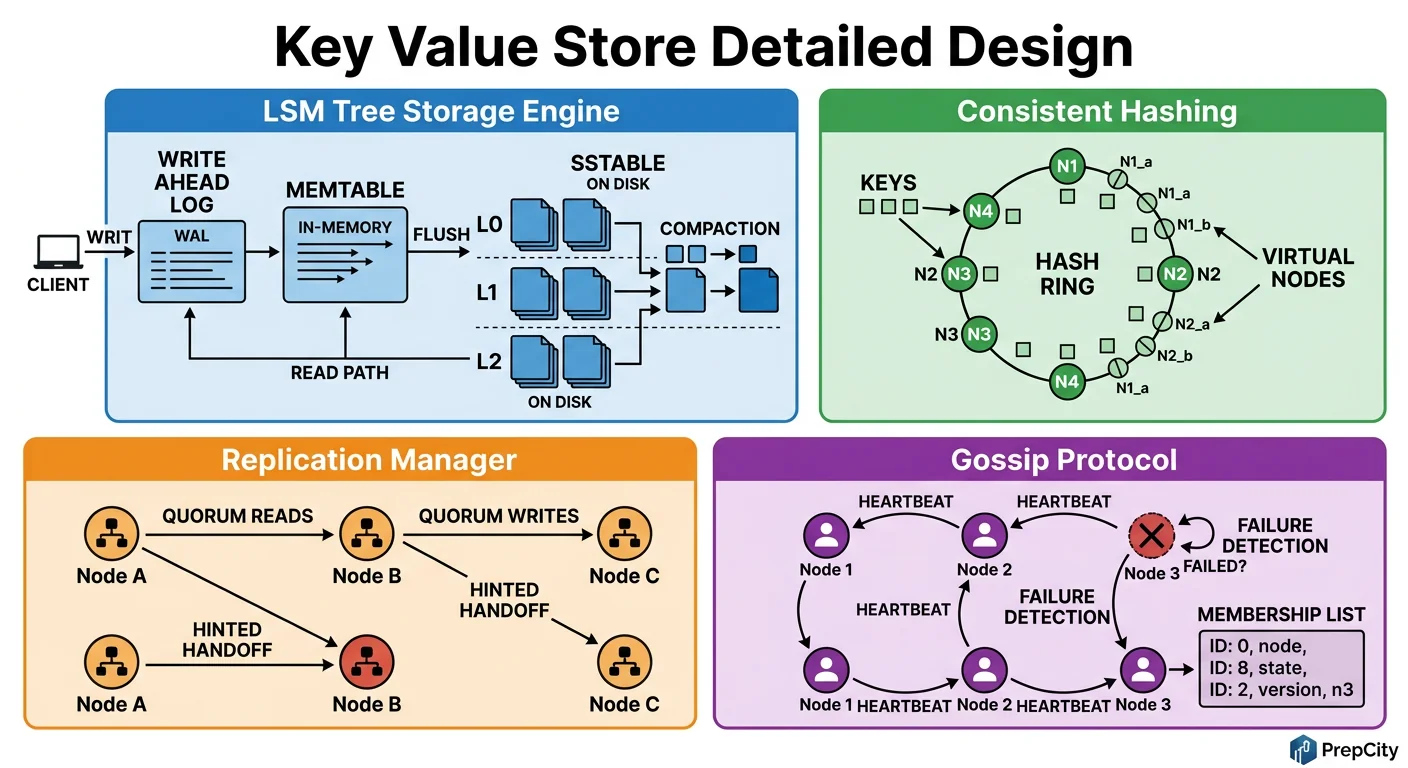
Detailed Component Design
Three components are worth going deep on: the consistent hashing ring, the storage engine, and the failure detection system.
Consistent Hashing with Virtual Nodes
Each physical node gets 150 virtual nodes (vnodes) placed at random positions on a 2^128 hash ring (using MD5 or MurmurHash3). When a key arrives, hash it and walk clockwise to find the first vnode - that's the primary. The next 2 distinct physical nodes clockwise are the replicas.
Why 150 vnodes? Fewer vnodes cause uneven load distribution. More vnodes increase memory overhead and slow down ring recalculation. 150 is the sweet spot - Cassandra uses 256 by default, DynamoDB uses ~30 with more sophisticated placement. At 50 nodes à - 150 vnodes = 7,500 ring entries - trivially fits in memory.
When a node joins, it takes ownership of its vnodes' ranges. Existing nodes stream data for those ranges to the new node. When a node leaves, its ranges are redistributed to clockwise neighbors. No data movement for unaffected ranges.
Storage Engine (RocksDB + WAL)
Every write follows this path
1. Append to write-ahead log (WAL) on disk - sequential write, fast 2. Insert into in-memory MemTable (a skip list) 3. When MemTable fills (64MB default), flush to an immutable SSTable on disk 4. Background compaction merges SSTables to reclaim space and maintain read performance
This is the LSM-tree pattern. It's write-optimized because all writes are sequential (WAL append + MemTable insert). Reads check MemTable first, then SSTables with a Bloom filter to skip irrelevant files.
Why RocksDB over B-tree databases (PostgreSQL, InnoDB)? B-trees require random I/O for writes, which limits write throughput on SSDs to ~10K ops/sec. LSM trees sustain 50K+ writes/sec on the same hardware because every write is sequential.
Failure Detection (Gossip + Phi Accrual)
Every node gossips with 3 random peers every second, exchanging heartbeat counters and membership info. Use the Phi Accrual failure detector (same as Cassandra) instead of a fixed timeout. It calculates a "suspicion level" (phi) based on heartbeat arrival patterns. When phi > 8 (configurable), the node is marked as suspected-down.
Why not a centralized health checker (like ZooKeeper)? It becomes a single point of failure and doesn't scale past ~1,000 nodes. Gossip scales to tens of thousands of nodes with O(log N) convergence time.
When a node is marked down, its vnodes' ranges are temporarily handled by the next nodes clockwise (hinted handoff). Writes destined for the dead node are stored as "hints" on the neighbor. When the node recovers, hints are replayed. If it doesn't recover within 3 hours, a full replacement is triggered.
Data Model & Database Design
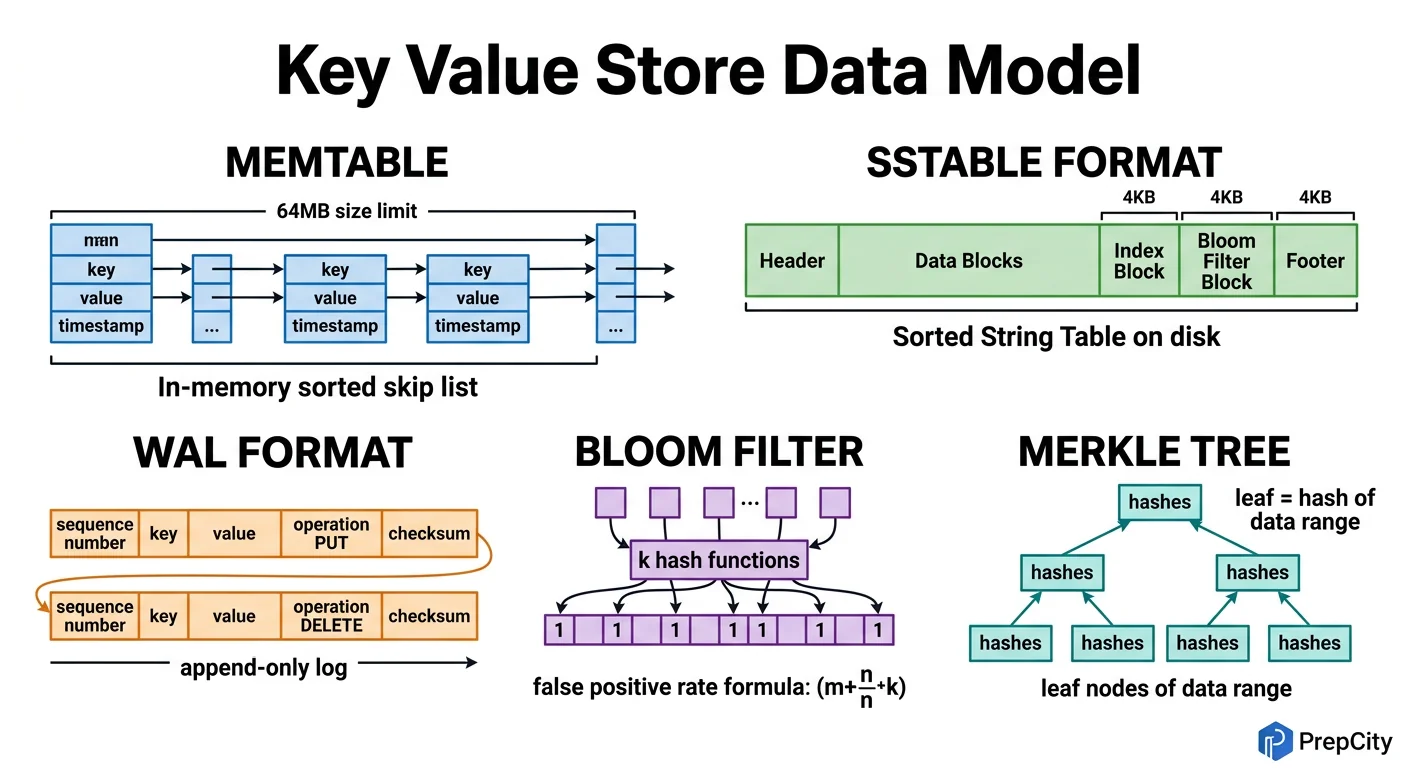
Data Model & Database Design
This is a key-value store, so the "data model" is deceptively simple. The complexity lives in how data is organized on disk and replicated across nodes.
On-Disk Format (per node)
Each key-value pair is stored as a record
- -key: variable-length bytes (max 256B)
- -value: variable-length bytes (max 1MB)
- -version: uint64 - monotonically increasing per key, per node
- -timestamp: uint64 - wall-clock milliseconds, used for LWW conflict resolution
- -tombstone: bool - true means deleted (needed for distributed deletes)
- -ttl_expiry: uint64 - 0 means no expiry
RocksDB stores these as sorted key-value pairs. The sort key is (key_bytes, version_desc) so the newest version of a key is always first. Old versions are garbage-collected during compaction.
Partitioning
Consistent hashing on the key determines which 3 nodes store the data. No range partitioning - pure hash partitioning. This means:
- -Uniform distribution regardless of key patterns
- -No range queries possible (by design)
- -Adding/removing nodes moves minimal data (~1/N of total)
Replication
Each key lives on 3 nodes (replication factor = 3). Writes go to all 3; reads go to 1, 2, or 3 depending on consistency level.
- -W=2, R=2 (quorum): guarantees you read your own writes (W + R > N)
- -W=1, R=1: fastest but allows stale reads
- -W=3, R=1: durable writes, fast reads, but write latency increases
Conflict Resolution
When replicas disagree, use Last-Write-Wins (LWW) with the timestamp field. This is simple and works for 99% of use cases. The tradeoff: if two clients update the same key simultaneously on different nodes, one write silently wins.
For use cases where silent data loss is unacceptable, support vector clocks as an opt-in. Vector clocks detect conflicts and return both versions to the client, who resolves it (this is what DynamoDB does with its "shopping cart" example). But vector clocks add metadata overhead (~20 bytes per node in the cluster per key) and push complexity to the client.
TTL Implementation
Store ttl_expiry in the record. A background process on each node scans for expired keys every 10 seconds and writes tombstones. Tombstones are garbage-collected after 72 hours (enough time for all replicas to see the delete via anti-entropy).
Deep Dives
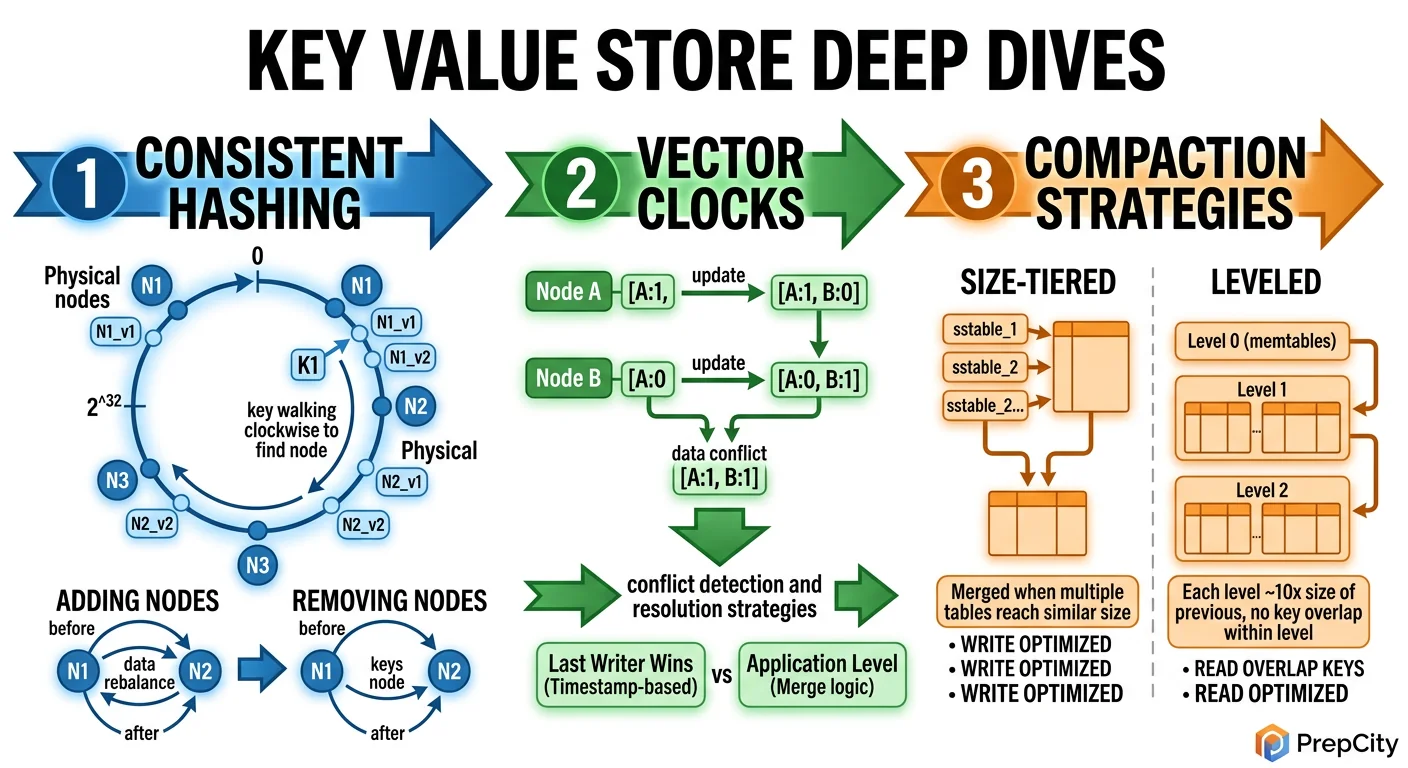
Deep Dives
Deep Dive 1: Handling Network Partitions
Problem: Your 50-node cluster splits into two groups of 25 due to a network partition. Both sides are running, both sides receive client traffic. What happens?
Approach: This is where the CAP theorem stops being theoretical. Since we chose AP (availability + partition tolerance), both sides continue serving reads and writes. Keys that are replicated across both sides of the partition will diverge.
When the partition heals, replicas sync up via anti-entropy (Merkle tree comparison). Conflicting writes are resolved by LWW - the write with the higher timestamp wins. This means some writes during the partition are silently discarded.
Tradeoff: If you need zero data loss during partitions, you'd need to switch to CP mode - reject writes to keys that can't reach a quorum. This is what etcd/ZooKeeper do. The cost is availability: during a partition, some keys become unwritable. For a general-purpose KV store, the AP choice is almost always correct.
Deep Dive 2: Hot Keys
Problem: A single key (e.g., a viral tweet's like count) gets 50K reads/sec. It lives on 3 nodes, but even with quorum reads hitting 2 of 3, each node handles ~33K reads/sec for this one key. That saturates the node.
Approach: Client-side caching with short TTL (1-5 seconds). The client library caches hot keys locally and serves reads from cache. This eliminates 95%+ of hot-key traffic before it hits the cluster.
For writes, use a different strategy: buffer writes in a per-node counter and flush periodically. Instead of 50K increment operations, do 50 batch increments of 1,000 each. This is the approach Facebook uses for like counts.
Tradeoff: Both approaches sacrifice freshness. A 5-second client cache means reads can be 5 seconds stale. Batched writes mean the count is eventually consistent. For social media counters, nobody notices. For bank balances, you'd need a different approach (strong consistency + single-leader replication for that key).
Deep Dive 3: Data Repair and Anti-Entropy
Problem: Over time, replicas drift. A node was down for 30 minutes, missed 100K writes, came back up. Hinted handoff covers writes that arrived during downtime, but what about writes that were dropped? How do you detect and fix divergence?
Approach: Merkle trees. Each node maintains a Merkle tree over its key ranges. Every 10 minutes, replicas exchange Merkle tree roots. If roots match, data is consistent. If not, they walk down the tree to find exactly which key ranges diverged, then stream only the differing keys.
This is extremely efficient: comparing two Merkle trees for 1 billion keys requires exchanging only ~20 tree levels à - a few KB each. The actual data transfer is proportional to the number of divergent keys, not the total dataset.
Tradeoff: Merkle trees use ~1% of total storage for tree nodes. Rebuilding the tree after a compaction takes a few seconds. The 10-minute sync interval means divergence can persist for up to 10 minutes. For tighter consistency, reduce the interval - but this increases network overhead.
Trade-offs & Interview Tips
Key Trade-offs:
- -AP vs. CP: We chose availability over consistency. This is the right default for most KV store use cases. If the interviewer's scenario requires strong consistency (distributed locks, leader election), pivot to a CP design with Raft consensus. Know both and explain when you'd pick each.
- -LWW vs. Vector Clocks: LWW is simple and loses conflicting writes silently. Vector clocks detect conflicts but push resolution to the client. Start with LWW, mention vector clocks as an upgrade path. DynamoDB started with vector clocks and later added LWW as the default because most users didn't want to handle conflicts.
- -LSM Tree vs. B-Tree storage: LSM trees (RocksDB) give better write throughput at the cost of read amplification. B-trees give better read performance at the cost of write amplification. For a KV store with 5:1 read:write ratio, LSM is still the right choice because the read amplification is mitigated by the block cache and Bloom filters.
- -Replication factor 3 vs. 5: RF=3 is standard. RF=5 survives 2 simultaneous node failures but uses 67% more storage and increases write latency. Use RF=5 only for critical data with strict durability requirements.
What I'd Do Differently
- -Use gRPC instead of REST from the start. Key-value operations are high-frequency and low-payload - exactly where gRPC's binary encoding and HTTP/2 multiplexing shine. REST is easier to debug but adds ~2ms of overhead per request from JSON serialization alone.
- -Implement a separate "coordinator" tier instead of having every node act as coordinator. It simplifies the codebase and makes it easier to scale the coordination layer independently.
Common Interview Mistakes
- -Jumping to "use DynamoDB" without explaining the internals. The interviewer wants to see you design the system, not pick a managed service.
- -Forgetting about tombstones for deletes. In a replicated system, you can't just remove a key - other replicas would think it still exists and "resurrect" it during anti-entropy.
- -Hand-waving consistency. You must be specific: quorum reads with W + R > N give you what guarantees exactly? (Read-your-writes, not linearizability.)
Interview Tips
- -Draw the consistent hashing ring early. It anchors the entire discussion and makes partitioning, replication, and failure handling concrete.
- -When discussing CAP, don't just state your choice - give a concrete scenario. "During a network partition between data centers, we continue serving reads and writes on both sides, and reconcile when the partition heals."
- -Mention Merkle trees for anti-entropy proactively. It separates senior candidates from junior ones.
- -If asked about strong consistency, explain the shift: replace gossip-based failure detection with Raft consensus, replace LWW with linearizable reads via leader leases. Basically, you'd be designing etcd instead of DynamoDB.
Ready to be interviewed on this?
Our AI interviewer will test your understanding with follow-up questions
Start Mock Interview