Design a URL Shortener (TinyURL)
A URL shortener is deceptively simple on the surface but forces you to make real decisions about ID generation, caching strategy, and read-heavy scaling. The core challenge: generate globally unique short keys at scale, serve redirects in under 50ms, and handle a 100:1 read-to-write ratio without melting your database.
Practice this design with AI
Get coached through each section in a mock interview setting
Problem Statement & Requirements
A URL shortener maps long URLs to short aliases and redirects users. The interesting engineering is in the read-heavy access pattern and the uniqueness constraint on short keys.
Functional Requirements
- -Given a long URL, generate a unique short URL (e.g., short.ly/x7Kp2)
- -Redirect short URL to the original long URL
- -Support optional custom aliases
- -Track basic click analytics (redirect count per link)
- -Expose a REST API for programmatic access
- -Deduplicate: if the same long URL is submitted twice, return the existing short URL
Non-Functional Requirements
- -100M DAU, with a 100:1 read-to-write ratio
- -Write QPS: ~12 avg, ~36 peak
- -Read QPS: ~1,200 avg, ~3,500 peak
- -p99 redirect latency < 50ms
- -p99 shortening latency < 200ms
- -99.99% availability
- -URLs are permanent unless explicitly deleted
- -Storage grows ~1M new URLs/day
Out of Scope
- -User auth (assume open access or API-key gated)
- -Advanced analytics (geo, referrer, device breakdown)
- -Link previews or social media integrations
Back-of-Envelope Estimation
Start with 100M DAU. About 1% create a short URL on any given day, so ~1M writes/day.
Write QPS
- -1,000,000 / 86,400 = ~12 writes/sec
- -Peak (3x): ~36 writes/sec
- -This is tiny. A single Postgres instance handles this easily.
Read QPS
- -Each shortened URL gets clicked ~100 times/day on average
- -1M URLs * 100 clicks = 100M reads/day
- -100,000,000 / 86,400 = ~1,160 reads/sec
- -Peak (3x): ~3,500 reads/sec
- -Manageable, but caching is still essential to hit the 50ms p99 target.
Storage
- -Each URL record: ~100 bytes (short key + long URL + timestamps + metadata)
- -Daily: 1M * 100B = 100 MB/day
- -Yearly: ~36 GB/year
- -After 5 years: ~180 GB. Fits on a single node, no exotic sharding needed initially.
Cache
- -80/20 rule: 20% of URLs get 80% of traffic
- -Cache the hot 200K URLs: 200K * 100B = ~20 MB
- -This is trivially small for Redis. A single instance handles this with room to spare.
Bandwidth
- -Redirect responses are tiny (~1KB with headers)
- -Peak: 3,500 * 1KB = ~3.4 MB/s
- -Not a concern.
Key takeaway: this is a read-heavy system with modest storage needs. The engineering challenge is latency, not throughput.
API Design
Three endpoints cover the core functionality. Auth via API key in the X-API-Key header. Rate limiting headers on every response.
Create Short URL
- -POST
/api/v1/urls - -Request:
- -Response (201 Created):
Redirect (the hot path)
- -GET
/{alias} - -Returns 301 (permanent) or 302 (temporary) redirect
- -Use 302 if you want analytics accuracy; 301 if you want to offload traffic to the browser cache. For most URL shorteners, 302 is the right call because you lose visibility with 301.
Get URL Info
- -GET
/api/v1/urls/{alias} - -Response:
- -404 if the alias does not exist.
Delete URL
- -DELETE
/api/v1/urls/{alias} - -Returns 204 No Content on success.
Skip the List URLs and Update URL endpoints in an interview unless asked. They add API surface without revealing architectural insight.
High-Level Architecture
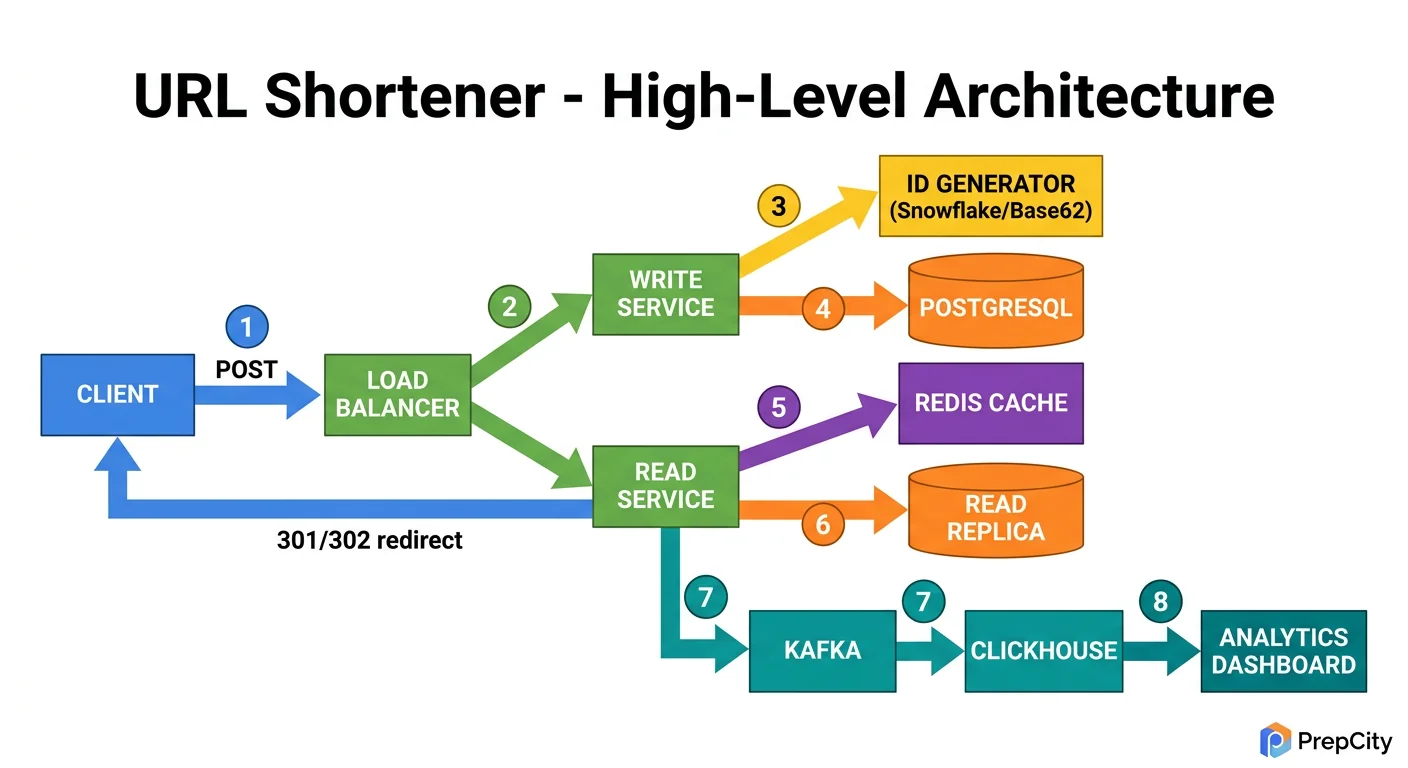
High-Level Architecture
Here is how a request flows through the system.
URL Shortening (write path)
1. Client POSTs to the load balancer with a long URL. 2. Load balancer routes to one of N stateless app servers. 3. App server generates a unique short key (Base62-encoded ID from a distributed counter in Redis). 4. App server writes the mapping to the primary database (PostgreSQL). 5. App server writes the same mapping to the Redis cache. 6. App server returns the short URL to the client.
URL Redirection (read path, the hot path)
1. Client hits short.ly/x7Kp2 through the load balancer. 2. App server checks Redis for the alias. Cache hit? Return a 302 redirect immediately. 3. Cache miss? Query PostgreSQL, populate the cache, then redirect. 4. Asynchronously increment the click counter (fire-and-forget to avoid adding latency to the redirect).
Components
- -Load Balancer: Round-robin across stateless app servers. Nothing fancy needed at this scale.
- -App Servers: Stateless, horizontally scalable. Handle shortening logic, cache lookups, and DB queries.
- -Redis: Cache layer for URL mappings. Also hosts the atomic counter (INCR) for ID generation.
- -PostgreSQL: Durable storage for all URL mappings. Single primary with read replicas if read QPS grows.
The entire read path should complete in one Redis lookup for the common case. That is how you hit the 50ms p99 target.
Detailed Component Design
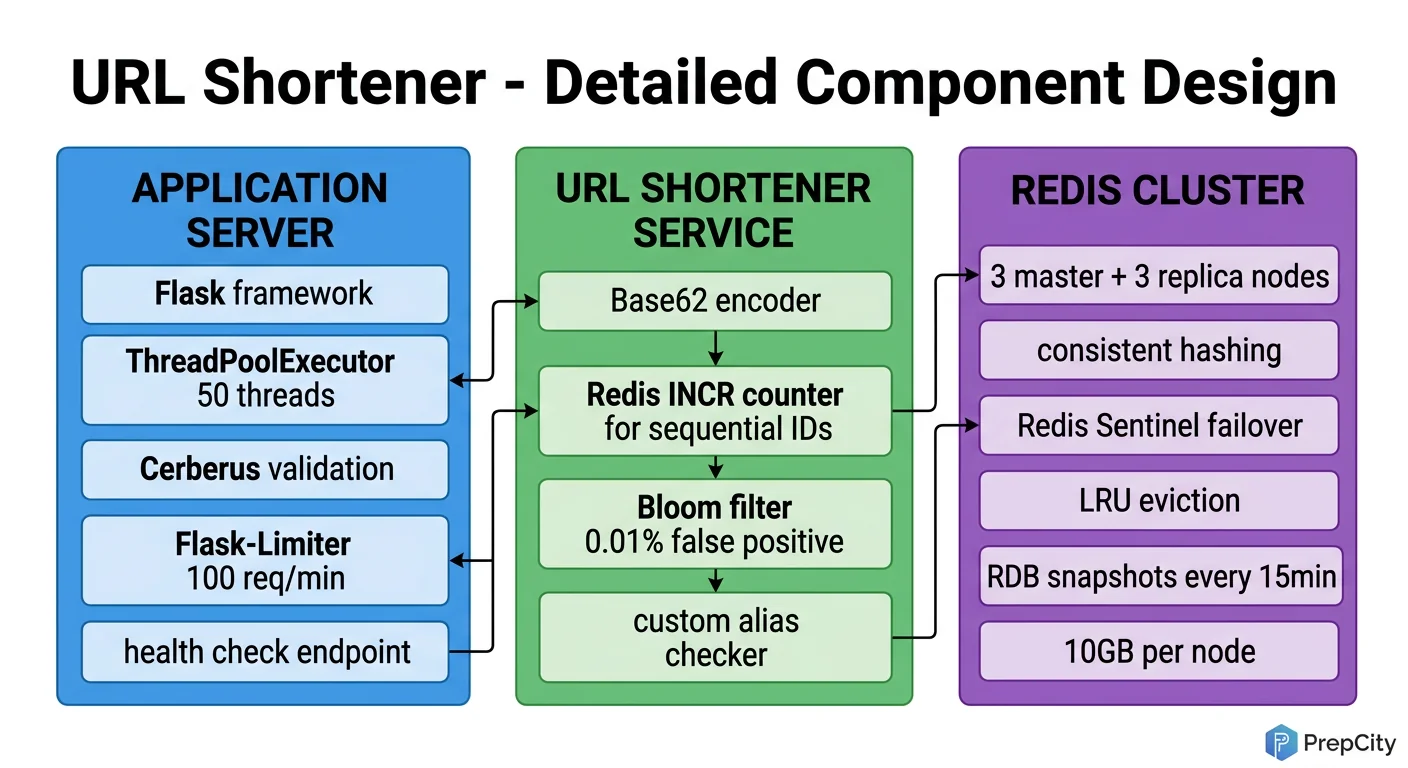
Detailed Component Design
Three components deserve a deep look: the ID generator, the cache layer, and the database.
ID Generator (the most interesting part)
- -Use a Redis INCR counter to produce a monotonically increasing 64-bit integer. Encode it as Base62 (a-z, A-Z, 0-9) to get a short, URL-safe string.
- -A 7-character Base62 key gives 62^7 = 3.5 trillion unique URLs. More than enough for decades.
- -Why not MD5/SHA and truncate? Hash collisions require retry logic, and the resulting keys are longer. Base62 on a sequential ID is simpler and collision-free by construction.
- -Why not UUID? UUIDs are 36 characters. The whole point is to be short.
- -Custom aliases bypass the counter entirely. Check if the alias exists in Redis first (O(1) lookup), then attempt a DB insert. If it collides, return a 409 Conflict.
Cache Layer (Redis)
- -Cache-aside pattern: read from cache first, fall back to DB, then populate cache on miss.
- -TTL of 24 hours on cache entries. The 80/20 rule means most traffic hits a tiny working set.
- -Total cache footprint is ~20 MB (see estimation). A single Redis node handles this trivially, but run a replica for availability.
- -For the click counter, use a separate Redis key with INCR. Flush to PostgreSQL in batches every 60 seconds. This keeps the redirect path fast and avoids write amplification on the DB for every click.
Database (PostgreSQL)
- -Single table: urls(id BIGSERIAL PK, alias VARCHAR(10) UNIQUE, long_url TEXT, created_at TIMESTAMPTZ, user_id BIGINT).
- -The UNIQUE constraint on alias is your last line of defense against duplicates.
- -At ~36 GB/year, a single PostgreSQL instance handles this for years. Add a read replica when read QPS exceeds what the primary can serve.
- -No sharding needed at this scale. If you ever hit the point where you need it, shard by hash of the alias.
Why these choices matter: the entire design optimizes for the read path. Writes are infrequent and can tolerate higher latency. Reads must be fast, so the cache sits in front of everything.
Data Model & Database Design
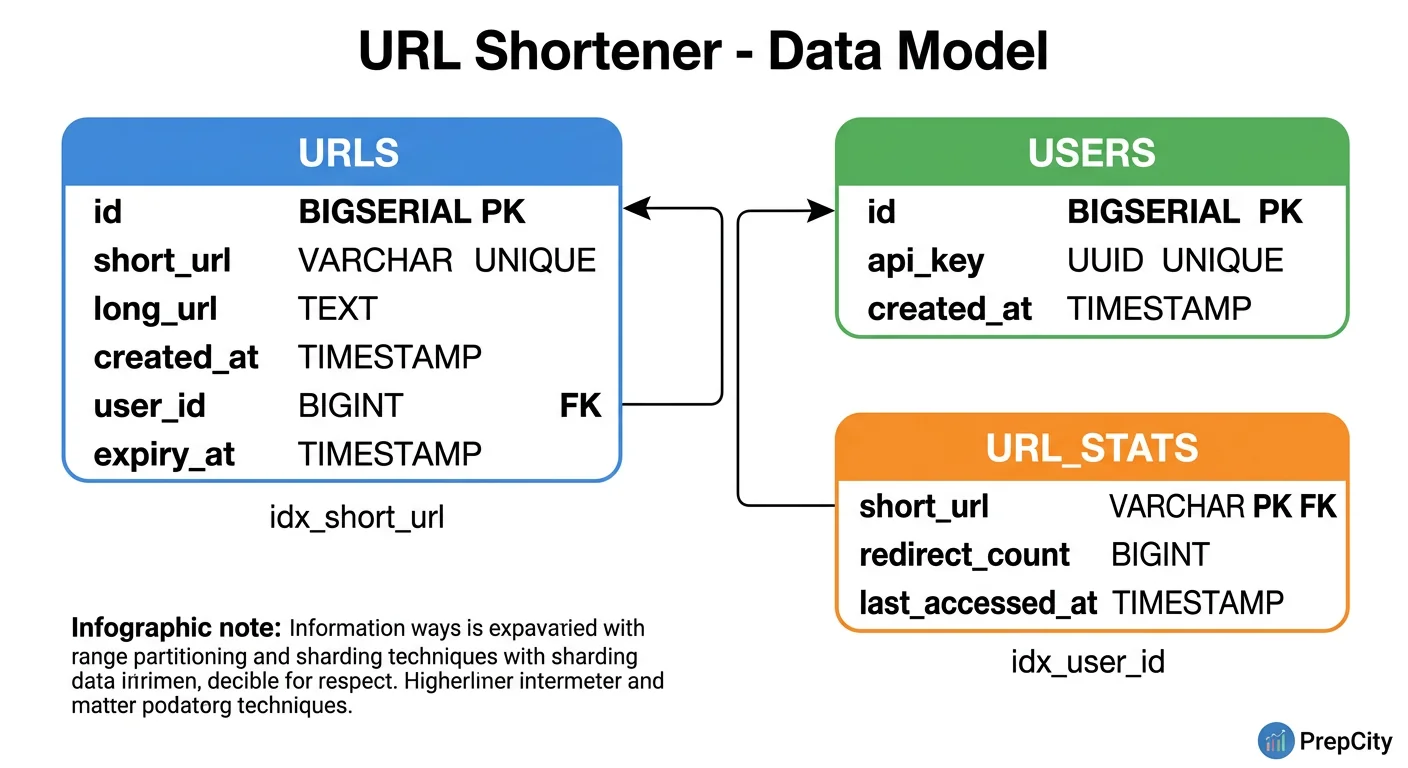
Data Model & Database Design
PostgreSQL is the right choice here. The data is relational (alias uniquely maps to a URL), the dataset is small, and you get ACID for free. NoSQL adds complexity without benefit at this scale.
Schema
urls table
url_stats table
Indexes
- -urls.alias: already covered by the UNIQUE constraint. This is the primary lookup key for redirects.
- -urls.user_id: B-tree index for "show me my links" queries.
- -urls.long_url: optional hash index for deduplication lookups ("does this long URL already have a short link?").
Why a separate url_stats table?
- -Redirect counts update on every click. Keeping them in the same row as the URL mapping means heavy write contention on a row that is mostly read.
- -Separate table lets you batch-update stats without locking the urls table.
- -In practice, stats writes go through Redis INCR and flush to PostgreSQL periodically.
Partitioning
- -Not needed initially. 36 GB/year fits comfortably on a single node.
- -If you reach hundreds of GBs, range-partition by created_at for easy archival of old links.
- -Sharding by hash(alias) is straightforward if you ever need horizontal scaling.
Deduplication
- -On INSERT, check if long_url already exists (using the hash index). If yes, return the existing alias.
- -This is an optimization, not a hard requirement. Some URL shorteners intentionally create new aliases every time for per-user analytics.
Deep Dives
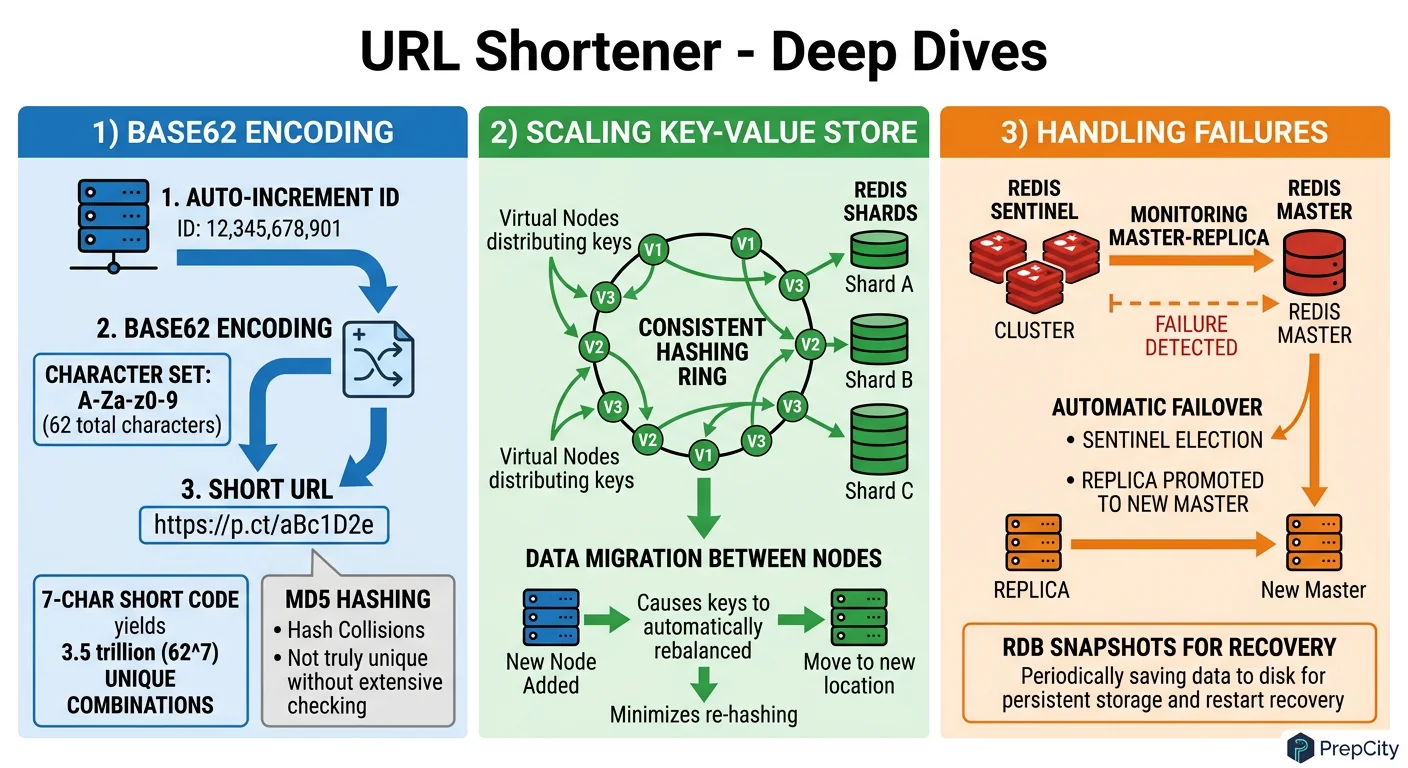
Deep Dives
Deep Dive 1: Base62 vs. Hashing for Key Generation
Problem: You need globally unique, short, URL-safe keys at ~1M/day.
Approach A - Hash and truncate: Take MD5(long_url), grab the first 7 characters. If it collides, append a counter and rehash. This is what bit.ly originally did.
Approach B - Sequential ID + Base62: Use an atomic counter (Redis INCR), encode the integer as Base62.
The right call is Base62 on a sequential ID
- -Zero collisions by construction. No retry logic.
- -Predictable key length (7 chars covers 3.5 trillion keys).
- -The counter is a single point of failure, but Redis INCR is atomic and survives restarts with AOF persistence. For extra safety, pre-allocate ID ranges to each app server (e.g., server 1 gets IDs 1-10000, server 2 gets 10001-20000). Now the counter is only hit when a range is exhausted.
Tradeoff: sequential IDs are guessable. If that matters, apply a bijective shuffle (like a Feistel cipher) to the ID before Base62 encoding. Same uniqueness guarantee, but the output looks random.
Deep Dive 2: 301 vs. 302 Redirects
Problem: Which HTTP status code should the redirect use?
301 (Moved Permanently): The browser caches the redirect. Subsequent clicks never hit your servers. Great for reducing load, terrible for analytics - you cannot count clicks you never see.
302 (Found / Temporary): The browser always checks with your server first. Every click is tracked, but your servers handle every request.
Use 302 by default. Analytics are the entire business model for most URL shorteners. If a specific use case needs maximum performance and does not care about click tracking, offer 301 as an opt-in flag on the API.
Deep Dive 3: Handling Hot Keys
Problem: A viral tweet contains your short link. Suddenly one key gets 100K requests/second.
Approach: The Redis cache already handles this for the read path. But if a single Redis key gets hammered, even Redis can struggle (hot key problem).
Solution: replicate hot keys across multiple Redis nodes. Use a client-side approach: append a random suffix (e.g., alias:1 through alias:10) and distribute reads across these replicas. The app server picks a random suffix on each request.
Alternatively, put a CDN in front of the redirect endpoint. Configure the CDN to cache 302 responses for 5-10 seconds. This absorbs traffic spikes without losing long-term analytics accuracy.
Trade-offs & Interview Tips
Key Trade-offs:
- -Base62 vs. Hashing: Base62 wins on simplicity and zero collisions. Hashing wins if you need deterministic mapping (same input always produces the same key without a DB lookup). Pick Base62 unless you have a specific reason not to.
- -Redis vs. Memcached for caching: Redis. It gives you atomic INCR for the counter, persistence for crash recovery, and richer data structures. Memcached is simpler but lacks these features.
- -Cache-aside vs. Write-through: Cache-aside. Write-through adds latency to every write for marginal benefit. With a 100:1 read-write ratio, optimizing the read path matters far more.
- -301 vs. 302: 302 unless the client explicitly opts into 301. Losing analytics visibility is almost never worth the reduced server load.
- -Single DB vs. Sharded: Single PostgreSQL instance for as long as possible. Sharding adds operational complexity that is not justified at 36 GB/year. Do not shard preemptively.
What I Would Do Differently at 100x Scale
- -Move the redirect endpoint behind a CDN with short TTLs.
- -Pre-allocate ID ranges to app servers to eliminate the Redis counter as a bottleneck.
- -Shard PostgreSQL by hash(alias) once the dataset exceeds a few TB.
- -Add a Bloom filter in front of the DB to reject invalid aliases without a DB round-trip.
Common Interview Mistakes
- -Jumping to sharding when the dataset fits on a laptop. Show you understand when complexity is warranted.
- -Choosing MD5 hashing without discussing collision handling.
- -Forgetting to separate the analytics write path from the redirect read path.
- -Not mentioning 301 vs. 302 - this is a strong signal that you have worked with real systems.
Interview Tips
- -Start by nailing down the read-to-write ratio. It drives every architectural decision.
- -Sketch the read path first since it is the hot path.
- -Mention the ID generation tradeoffs proactively - interviewers love this topic.
- -If time permits, discuss how you would handle abuse (rate limiting, spam URLs, phishing detection).
Ready to be interviewed on this?
Our AI interviewer will test your understanding with follow-up questions
Start Mock Interview