Design a Chat System (WhatsApp / Messenger)
A chat system is fundamentally a real-time message routing problem. The hard parts are maintaining millions of persistent WebSocket connections, guaranteeing message delivery even when recipients are offline, ordering messages correctly in group chats, and keeping presence status accurate across a distributed fleet of servers.
Practice this design with AI
Get coached through each section in a mock interview setting
Problem Statement & Requirements
A chat system routes messages between users in real time. The core tension is between delivery speed (users expect messages in under 200ms) and reliability (losing a message is unacceptable).
Functional Requirements
- -1:1 text messaging between users
- -Group chats (up to 500 members)
- -Online/offline presence indicators
- -Message delivery receipts: sent, delivered, read
- -Push notifications for offline users
- -Message history with pagination
- -Media attachments (images, files) via pre-signed upload URLs
Non-Functional Requirements
- -500M DAU, 100M concurrent connections at peak
- -Average user sends 40 messages/day
- -Message delivery p99 < 200ms for online recipients
- -99.99% availability (< 53 min downtime/year)
- -Zero message loss - if it was sent, it must be delivered eventually
- -Storage: ~20B messages/day = ~20 TB/day at ~1 KB/message
- -Messages retained for 5 years minimum
Out of Scope
- -End-to-end encryption implementation details
- -Voice and video calling
- -Message editing, deletion, or reactions
Back-of-Envelope Estimation
500M DAU, each sending 40 messages/day on average.
Message Volume
- -500M * 40 = 20 billion messages/day
- -20B / 86,400 = ~230K messages/sec average
- -Peak (3x): ~700K messages/sec
This is serious throughput. A single database cannot handle this. You need a distributed message store from day one.
Storage
- -Average message: ~1 KB (content + metadata + indexes)
- -Daily: 20B * 1 KB = 20 TB/day
- -Monthly: 600 TB
- -Yearly: 7.2 PB
- -5-year retention: 36 PB
This is why WhatsApp uses a write-optimized store, not PostgreSQL. You need something like Cassandra or a custom LSM-tree based system.
Connections
- -100M concurrent WebSocket connections at peak
- -Each connection uses ~10 KB of server memory
- -100M * 10 KB = 1 TB of memory just for connections
- -At 500K connections per server, you need ~200 WebSocket servers
Bandwidth
- -700K messages/sec * 1 KB = 700 MB/sec inbound
- -Fan-out for group messages multiplies outbound bandwidth
- -A 100-person group chat means one inbound message creates 99 outbound deliveries
Presence
- -500M users updating status periodically
- -Heartbeat every 30 seconds: 500M / 30 = ~17M status updates/sec
- -This is the sneaky scaling challenge. Presence generates more traffic than messaging itself.
API Design
The chat system uses two protocols: WebSocket for real-time messaging and REST for everything else. This split is intentional - WebSocket gives you bidirectional streaming for messages, while REST handles stateless operations like creating groups or fetching history.
WebSocket Events (bidirectional)
Client to server
- -send_message: { "to": "user123", "content": "hello", "type": "text", "client_msg_id": "uuid" }
- -send_group_message: { "group_id": "g456", "content": "hello", "type": "text", "client_msg_id": "uuid" }
- -typing: { "to": "user123" }
- -ack: { "message_id": "msg789", "status": "delivered" | "read" }
- -heartbeat: { } (every 30 seconds to maintain presence)
Server to client
- -new_message: { "message_id": "msg789", "from": "user456", "content": "hey", "sent_at": "..." }
- -delivery_receipt: { "message_id": "msg789", "status": "delivered" | "read" }
- -presence_update: { "user_id": "user123", "status": "online" | "offline" }
The client_msg_id is critical - it is a client-generated UUID for idempotency. If the client retries a send (e.g., after a network blip), the server deduplicates on this ID.
REST Endpoints
Fetch message history
- -GET
/api/v1/conversations/{conversation_id}/messages?before={cursor}&limit=50 - -Response: { "messages": [...], "next_cursor": "msg_abc" }
- -Use cursor-based pagination, not offset. Offset is O(n) on large tables.
Create group
- -POST
/api/v1/groups - -Request: { "name": "Engineering", "member_ids": ["u1", "u2", "u3"] }
- -Response: { "group_id": "g456", "created_at": "..." }
Get user presence
- -GET
/api/v1/users/{user_id}/presence - -Response: { "status": "online", "last_seen": "2024-01-26T11:55:00Z" }
High-Level Architecture
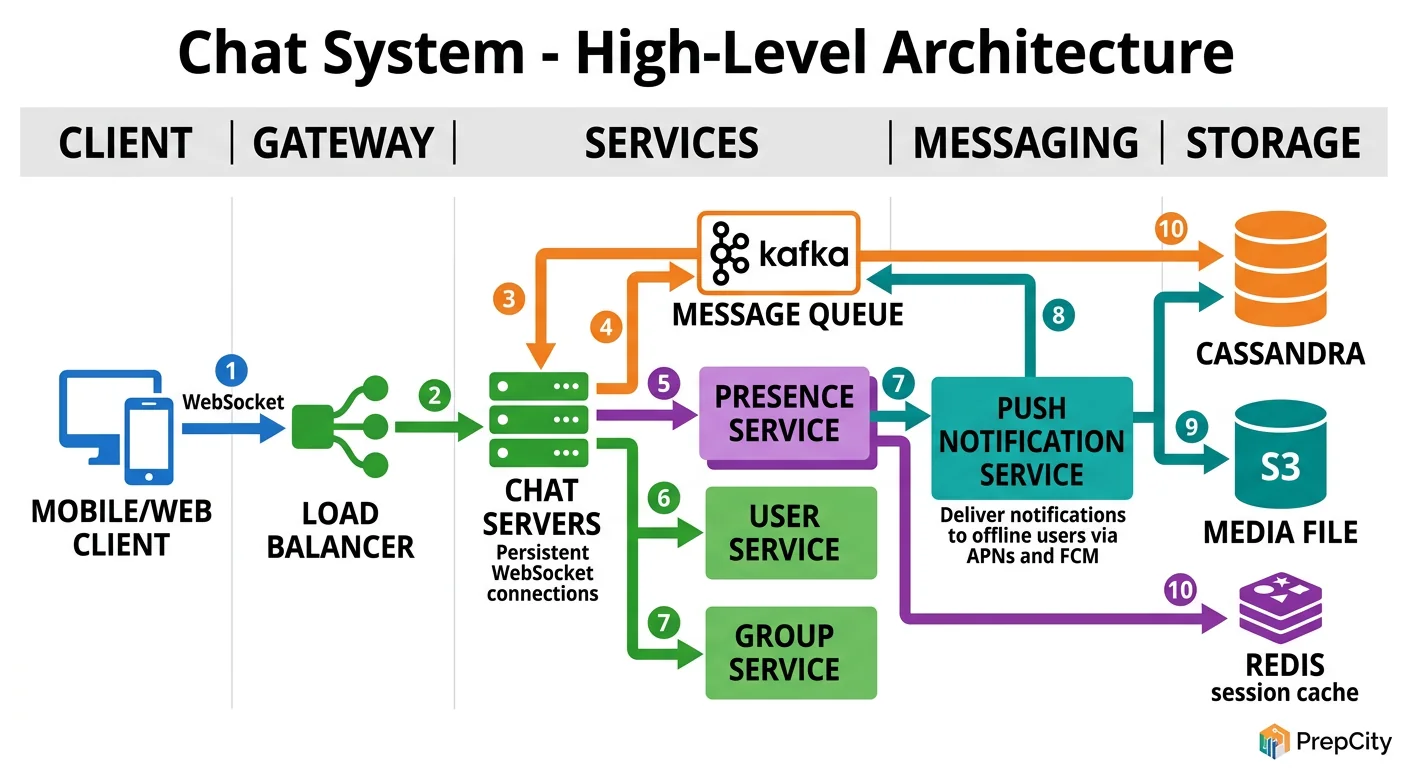
High-Level Architecture
Follow a message from sender to recipient to understand the architecture.
Sending a 1:1 message (the hot path)
1. Sender's phone sends a message over its WebSocket connection to a Gateway Server. 2. The Gateway Server authenticates the sender, assigns a server-side message_id and timestamp, and publishes the message to a Message Queue (Kafka). 3. A Message Router service consumes from Kafka. It looks up which Gateway Server the recipient is connected to (via the Session Service backed by Redis). 4. If the recipient is online: the Router pushes the message to the recipient's Gateway Server, which delivers it over the recipient's WebSocket. 5. If the recipient is offline: the Router writes the message to an Offline Message Store and triggers a push notification via APNs/FCM. 6. In parallel, a Storage Consumer writes the message to the persistent Message Store (Cassandra) for history.
Key components
- -Gateway Servers: Maintain WebSocket connections. Stateful (each connection is pinned to a server), so you need a Session Service to track which user is on which gateway.
- -Session Service (Redis): Maps user_id to gateway_server_id. Updated on connect/disconnect.
- -Kafka: Decouples the send path from the delivery path. Guarantees at-least-once delivery. Handles backpressure when recipients are slow.
- -Message Router: The brains. Reads from Kafka, looks up recipient location, routes accordingly.
- -Message Store (Cassandra): Write-optimized, horizontally scalable. Partitioned by conversation_id for efficient history queries.
- -Presence Service (Redis): Tracks online/offline status via heartbeats.
- -Push Notification Service: Sends notifications via APNs (iOS) and FCM (Android) for offline users.
Group messages fan out: the Router reads the group membership, then delivers to each online member individually. For large groups, this fan-out is the primary scaling bottleneck.
Detailed Component Design
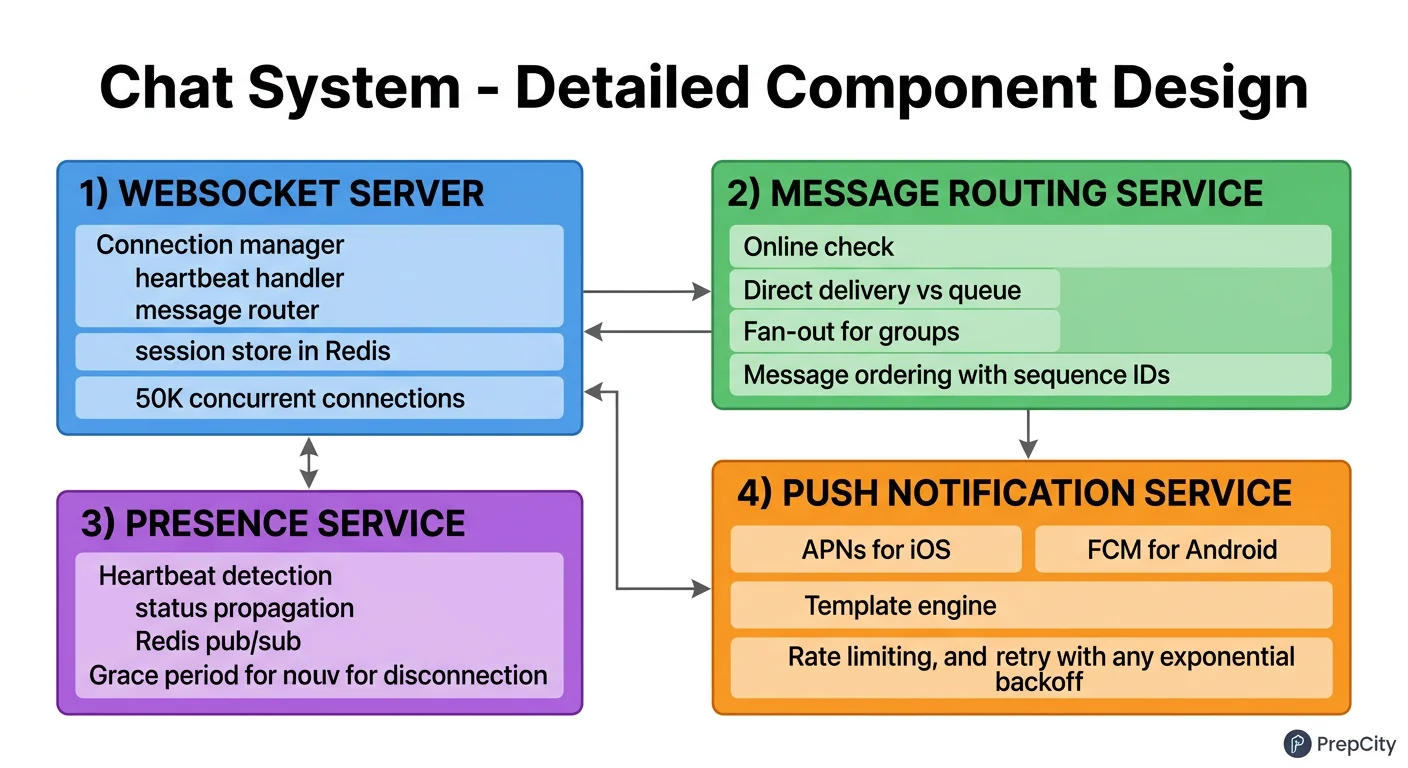
Detailed Component Design
Three components deserve a close look: the Gateway Server, the Message Router, and the Presence Service.
Gateway Server
- -Each server holds up to 500K concurrent WebSocket connections using an event-driven framework (Netty or Go with epoll).
- -Stateful by nature - a connection is pinned to one server. This means you cannot just round-robin load balance. Use a consistent hashing scheme or a connection-aware LB.
- -On connect: register (user_id, gateway_id) in the Session Service (Redis). On disconnect: remove it.
- -Gateway servers are the only component that talks directly to clients. Everything behind them is internal.
- -Why not just HTTP long-polling? WebSocket gives you true bidirectional streaming with lower overhead. Long-polling wastes bandwidth on repeated headers and has higher latency. At 100M concurrent connections, that overhead matters.
Message Router
- -Consumes from Kafka, one consumer group per data center.
- -For each message: look up the recipient's gateway in the Session Service. If found, forward over an internal gRPC connection to that gateway. If not found, write to the offline store and trigger a push notification.
- -Group fan-out: fetch the member list, filter out the sender, and deliver to each member. For a 500-person group, that is 499 individual deliveries. Batch the gRPC calls to the same gateway to reduce round-trips.
- -Idempotency: the client_msg_id from the sender deduplicates retries. The Router checks a short-lived dedup cache (Redis, 5-minute TTL) before processing.
- -Why Kafka and not direct delivery? Kafka absorbs traffic spikes, provides durability (messages survive Router crashes), and enables replay for debugging. Direct delivery (gateway-to-gateway) is faster but loses messages if the recipient's gateway is temporarily down.
Presence Service
- -Clients send a heartbeat every 30 seconds over WebSocket. The Gateway Server batches these and updates Redis with a 60-second TTL on each user's presence key.
- -If a heartbeat is missed (key expires), the user is marked offline.
- -Subscribing to presence updates: when user A opens a chat with user B, the client subscribes to B's presence. Use Redis Pub/Sub - publish a presence change event to a channel named after the user_id. Only users actively viewing that contact receive updates.
- -Why not broadcast presence to all contacts? A user with 500 contacts would trigger 500 notifications every time they come online. At 500M DAU, that is catastrophic fan-out. Subscribe-on-view limits this to the contacts you are actually looking at.
Data Model & Database Design
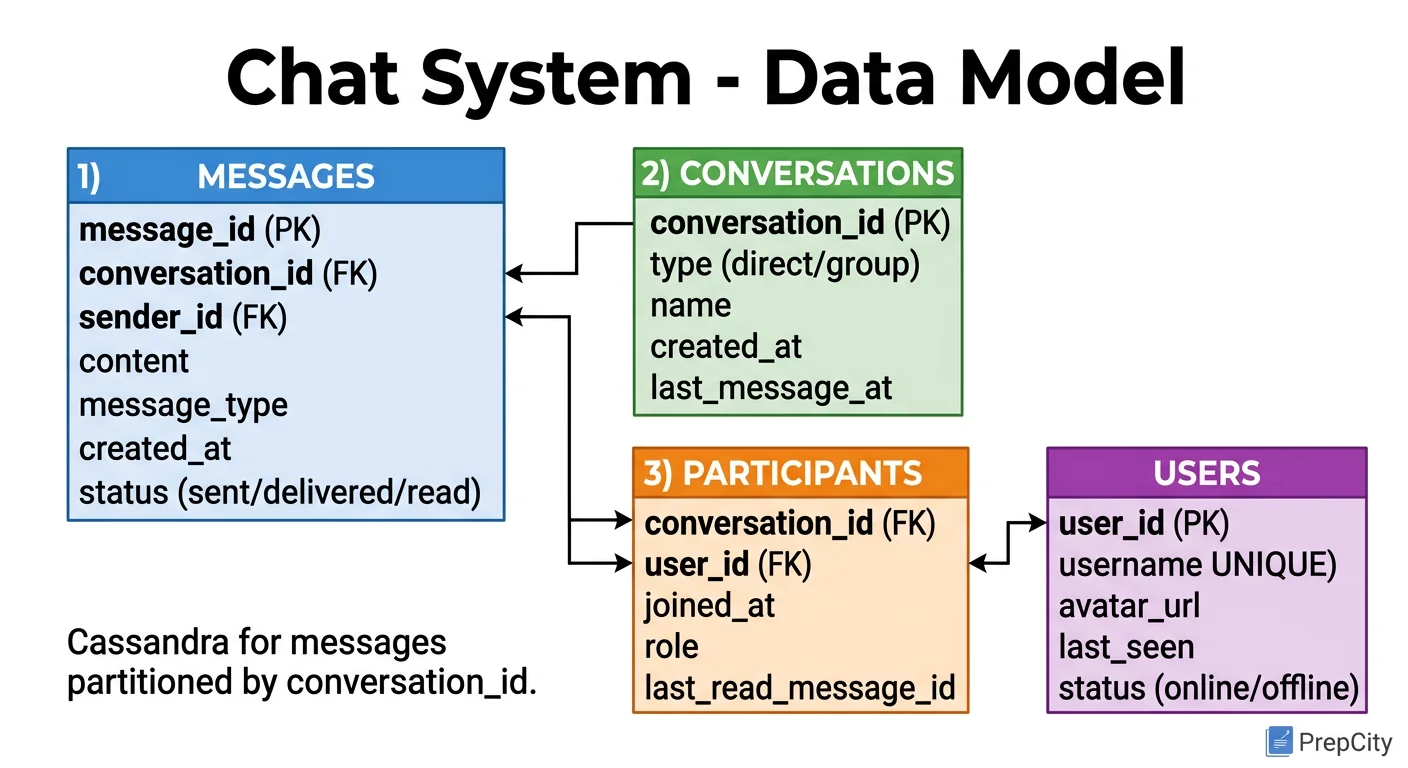
Data Model & Database Design
Use Cassandra for the message store, not PostgreSQL. At 20 TB/day, you need a database built for high write throughput and horizontal scaling. Cassandra delivers both.
Messages Table (Cassandra)
- -Partition key: conversation_id (a deterministic hash of sorted user IDs for 1:1, or the group_id for groups)
- -Clustering key: message_id (a time-ordered UUID like ULID or Snowflake ID)
- -Columns: sender_id, content, message_type, sent_at, delivered_at, read_at
This partition design means all messages in a conversation live on the same partition, sorted by time. Fetching the last 50 messages is a single-partition range scan - extremely fast in Cassandra.
Conversations Table (Cassandra)
- -Partition key: user_id
- -Clustering key: last_message_at (descending)
- -Columns: conversation_id, other_user_id or group_id, last_message_preview, unread_count
This powers the inbox view: "show me my conversations sorted by most recent activity." One partition scan per user.
Groups Table (PostgreSQL)
- -group_id (UUID PK), name, creator_id, created_at
- -group_members: (group_id, user_id) composite PK, joined_at
- -Group metadata is low-volume and relational. PostgreSQL is the right tool here.
Users Table (PostgreSQL)
- -user_id (UUID PK), username, password_hash, email, created_at
Why Cassandra for messages but PostgreSQL for groups/users?
- -Messages are write-heavy (20 TB/day), append-only, and accessed by partition key. Cassandra excels here.
- -Groups and users are low-volume, need referential integrity, and benefit from JOINs. PostgreSQL excels here.
- -Using the right database for each access pattern is better than forcing one database to do everything.
Indexing
- -Cassandra: partition key (conversation_id) handles the primary access pattern. No secondary indexes needed - they perform poorly in Cassandra at scale.
- -PostgreSQL: B-tree on group_members(user_id) for "which groups am I in" lookups.
Partitioning
- -Cassandra handles partitioning natively via consistent hashing on the partition key.
- -For the conversations table, partition by user_id. Hot users (celebrities) may create large partitions - consider bucketing by time (user_id + month) if partitions exceed 100 MB.
Deep Dives
Deep Dives
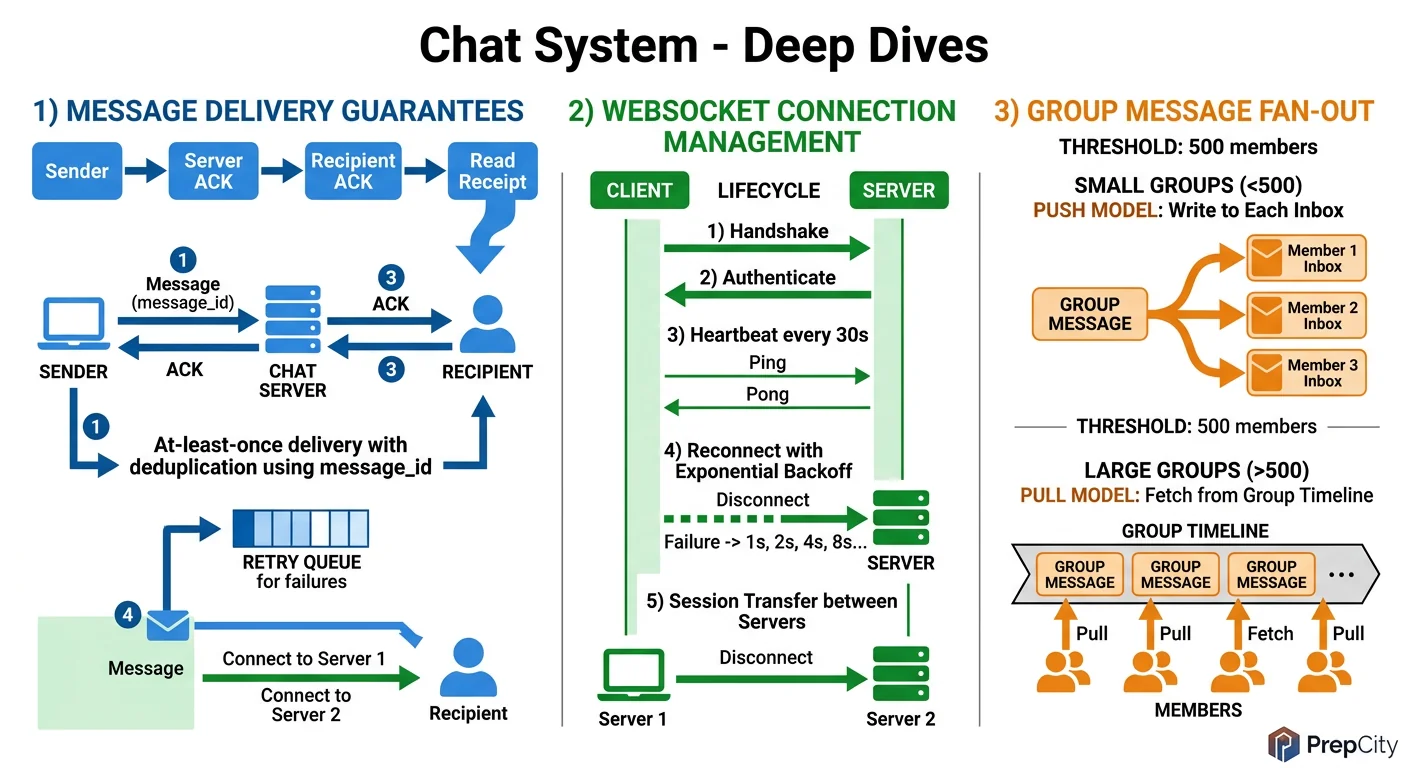
Deep Dive 1: Message Ordering in Group Chats
Problem: Two users send messages to a group at the same time. Different members may see them in different orders, breaking conversation coherence.
Approach: Assign each message a globally ordered ID at the point of ingestion. Use a Snowflake-style ID: 41 bits for timestamp (ms precision) + 10 bits for machine ID + 12 bits for sequence number. This gives you ~4096 messages/ms per machine with guaranteed uniqueness and rough time ordering.
For strict ordering within a group, route all messages for a given group_id to the same Kafka partition (use group_id as the partition key). Kafka guarantees ordering within a partition. The tradeoff: a very active group becomes a hot partition. If one group produces 10K messages/sec, that single partition becomes a bottleneck.
Mitigation: most groups are small and low-traffic. For the rare mega-group (thousands of members, high activity), consider a dedicated Kafka topic with multiple partitions and a sub-ordering scheme within the group.
Deep Dive 2: Offline Message Delivery
Problem: User B is offline when user A sends a message. When B comes back online, they need to receive all missed messages, in order, without duplicates.
Approach: When the Message Router cannot find B in the Session Service, it writes the message to an Offline Message Store (a Cassandra table partitioned by recipient_id, clustered by message_id). It also triggers a push notification.
When B reconnects, the Gateway Server queries the Offline Store for all messages with message_id > B's last_seen_message_id. These are delivered over the WebSocket, and the Offline Store entries are tombstoned.
The subtle part: B might reconnect to a different Gateway Server than before. The new Gateway must know B's last_seen_message_id. Store this in the Session Service (Redis) alongside the gateway mapping. On disconnect, persist the last acknowledged message_id.
Tradeoff: Cassandra tombstones accumulate and slow down reads over time. Run compaction regularly, and consider TTLing offline messages (e.g., 30 days) with a separate cold-storage archive for older undelivered messages.
Deep Dive 3: Scaling the WebSocket Layer
Problem: 100M concurrent connections across 200 servers. How do you handle server failures, deployments, and rebalancing without dropping messages?
Approach: Graceful shutdown is essential. When a Gateway Server is being drained (for deployment or scaling down), it sends a "reconnect" signal to all connected clients. Clients reconnect to a different server via the load balancer. The new server registers the updated mapping in the Session Service.
During the reconnection window (a few seconds), messages for these users go to the Offline Store. Once the client reconnects and pulls from the Offline Store, there is no message loss.
For server crashes (ungraceful), the Session Service entries have a TTL (e.g., 90 seconds). When the TTL expires, the Router treats the user as offline. The client's built-in reconnection logic (exponential backoff) establishes a new connection to a healthy server.
Tradeoff: the TTL creates a window where messages might be routed to a dead server. Keep the TTL short (60-90 seconds) and have the Router fall back to the Offline Store on delivery failure.
Trade-offs & Interview Tips
Key Trade-offs:
- -WebSocket vs. Long-Polling: WebSocket, no question. Long-polling wastes bandwidth and adds latency. The only argument for long-polling is firewall compatibility in restricted corporate networks, and even that is increasingly rare.
- -Kafka vs. Direct Gateway-to-Gateway: Kafka adds ~5-10ms of latency but gives you durability, backpressure handling, and replay. Direct delivery is faster but loses messages when a gateway is down. Use Kafka.
- -Cassandra vs. PostgreSQL for messages: Cassandra. At 20 TB/day, PostgreSQL sharding becomes an operational nightmare. Cassandra was designed for this write pattern. Use PostgreSQL for the low-volume relational data (users, groups).
- -At-Least-Once vs. Exactly-Once delivery: At-least-once with client-side deduplication (via client_msg_id). Exactly-once across distributed systems requires distributed transactions, which kill throughput. Dedup on the client is cheap and effective.
- -Fan-out on write vs. fan-out on read for group messages: Fan-out on write (deliver to each member individually). Fan-out on read (each member pulls from a shared inbox) reduces write amplification but adds read latency. For a chat system where delivery speed matters, fan-out on write is the right call.
What I Would Do Differently at 10x Scale
- -Shard the Session Service (Redis Cluster) by user_id hash.
- -Add regional Gateway Server clusters with cross-region message routing to reduce latency for international users.
- -Implement message compression (e.g., zstd) on the WebSocket layer to reduce bandwidth.
- -Build a dedicated media pipeline with chunked uploads, CDN delivery, and thumbnail generation.
Common Interview Mistakes
- -Using REST for real-time messaging. REST is request-response; chat needs bidirectional streaming.
- -Forgetting the offline delivery path. If you only design for online users, you have designed half a chat system.
- -Ignoring presence scaling. Presence generates more traffic than messaging. Mention the subscribe-on-view optimization.
- -Putting all data in one database. Chat systems need polyglot persistence - different stores for different access patterns.
Interview Tips
- -Start with the message flow for 1:1 chat. Get that right, then extend to groups.
- -Draw the WebSocket connection and show how a message traverses from sender to recipient through the Gateway, Kafka, Router, and back to a Gateway.
- -Mention idempotency (client_msg_id) early - it shows you think about real failure modes.
- -When discussing groups, quantify the fan-out problem. "A 500-person group means 499 deliveries per message" makes the scaling challenge concrete.
Ready to be interviewed on this?
Our AI interviewer will test your understanding with follow-up questions
Start Mock Interview