Design a News Feed (Twitter / Facebook)
A news feed is the central nervous system of any social platform. The core challenge: when a user with 10 million followers posts, how do you get that post into everyone's feed within seconds? This walkthrough covers fan-out strategies, feed ranking, caching at scale, and the hybrid push/pull architecture that powers Twitter and Facebook.
Practice this design with AI
Get coached through each section in a mock interview setting
Problem Statement & Requirements
The hard part of a news feed isn't showing posts in reverse chronological order. It's doing it for 500 million users, each following hundreds of accounts, while keeping latency under 200ms and incorporating a ranking algorithm that makes the feed feel personalized.
Functional Requirements
- -Users can publish posts (text, images, video links)
- -Users can follow/unfollow other users
- -Each user sees a personalized feed of posts from people they follow
- -Feed supports likes and comments with visible counts
- -Feed supports cursor-based pagination for infinite scroll
- -New posts appear in followers' feeds within 5 seconds for active users
Non-Functional Requirements
- -500M DAU, average user follows 200 accounts
- -Read-heavy: 100K QPS for feed reads, 10K QPS for post writes
- -p99 feed latency < 200ms
- -99.99% availability (52 min downtime/year)
- -~1 billion new posts/day, ~2KB average post size = ~2TB new data daily
- -Eventual consistency acceptable for like/comment counts; feed itself should reflect new posts within seconds
Out of Scope
- -Authentication/authorization (separate service)
- -Content moderation pipeline
- -The ranking model internals (treat as a black box that scores posts)
Back-of-Envelope Estimation
Starting with 500M DAU and working through the numbers.
Write volume
- -Average 2 posts per user per day = 1 billion posts/day
- -Average write QPS: 1B / 86,400 = ~11,500 posts/sec
- -Peak (3x): ~35K posts/sec
Read volume
- -Each user opens feed ~5 times/day, fetches 20 posts each time
- -500M * 5 * 20 = 50 billion post reads/day
- -Average read QPS: 50B / 86,400 = ~580K reads/sec
- -Peak (3x): ~1.7M reads/sec
This is a 50:1 read-to-write ratio. Every design decision should optimize for reads.
Storage
- -1B posts/day * 2KB = 2TB/day, 60TB/month, 720TB/year
- -Media stored separately in S3; the post table holds metadata + S3 pointers
Feed cache
- -Cache the most recent 200 post IDs per user (not full post objects)
- -200 post IDs * 8 bytes = 1.6KB per user
- -500M users * 1.6KB = ~800GB of feed cache
- -Redis cluster with 10-15 nodes handles this comfortably
Bandwidth
- -Peak read: 1.7M req/sec * 40KB avg response (20 posts with metadata) = ~68 GB/s
- -This requires a CDN for media and aggressive caching at every layer
API Design
Three core endpoints. Use cursor-based pagination instead of offset-based - offset pagination breaks when new posts are inserted.
Publish a Post
- -POST
/api/v1/posts - -Request:
- -```json
- -
` - -Response (201):
- -```json
- -
`
Fetch Feed
- -GET
/api/v1/feed?cursor={last_post_id}&limit=20 - -Response (200):
- -```json
- -
`
Like a Post
- -POST
/api/v1/posts/{post_id}/likes - -Response (200):
- -```json
- -
`
The feed endpoint is the hot path. Everything else is secondary.
High-Level Architecture
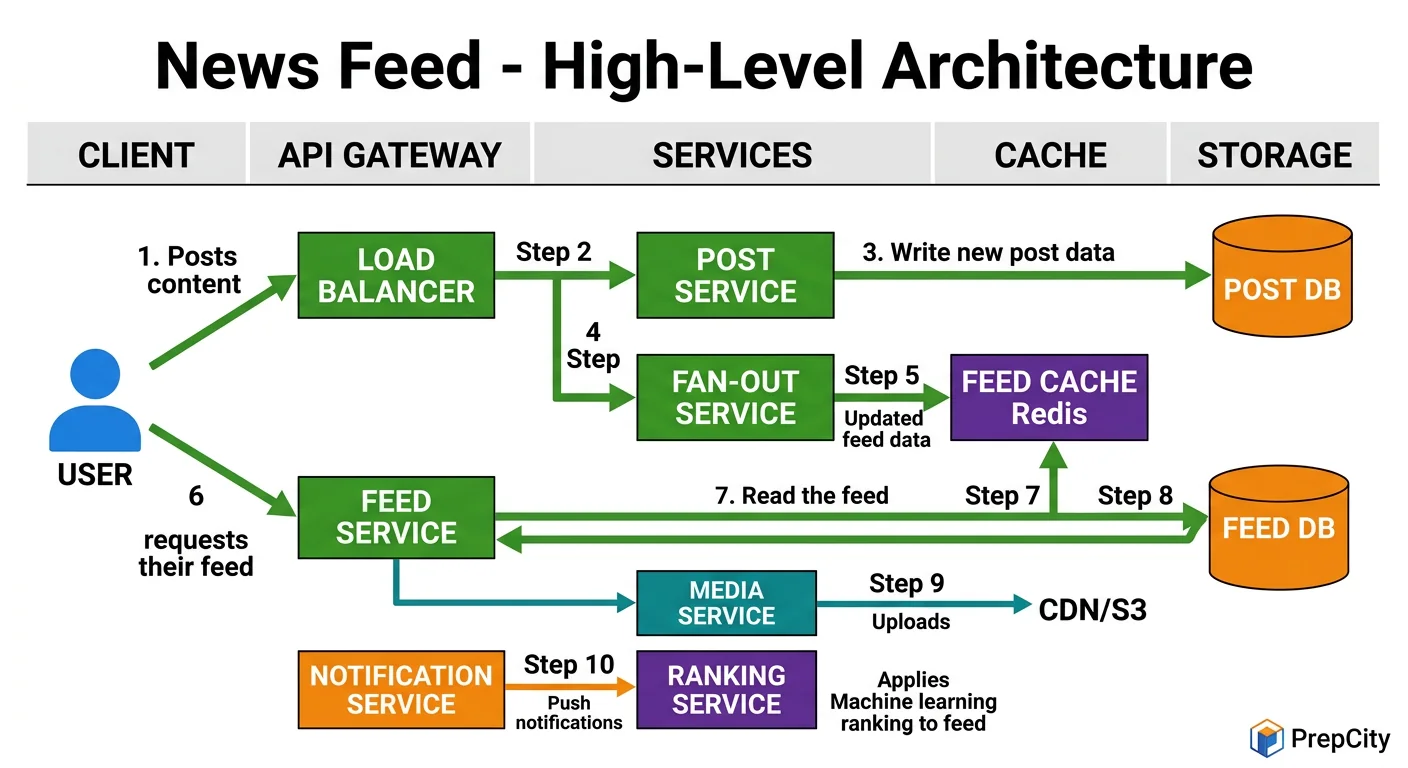
High-Level Architecture
The architecture splits into two distinct paths: the write path (publishing a post) and the read path (fetching a feed).
Write path - what happens when you post
1. Client sends POST to the API gateway behind a load balancer 2. Post Service validates the request, writes post to the Posts DB (PostgreSQL, sharded by user_id) 3. Post Service publishes a PostCreated event to Kafka 4. Fan-out Service consumes the event, looks up the author's follower list from the Social Graph Service 5. For each follower, the Fan-out Service pushes the post_id into that follower's feed list in Redis
Read path - what happens when you open your feed
1. Client sends GET /feed to the API gateway 2. Feed Service checks Redis for the user's pre-computed feed (list of post_ids) 3. Feed Service hydrates the post_ids by fetching full post objects from the Post Cache (Redis) or Posts DB 4. Ranking Service scores and reorders the posts based on relevance signals 5. Response returns to the client
Key components
- -Post Service: owns post CRUD, writes to PostgreSQL
- -Fan-out Service: async workers consuming from Kafka, pushing post_ids to follower feeds in Redis
- -Social Graph Service: manages follow relationships, backed by a graph store or sharded MySQL
- -Feed Cache (Redis): stores per-user feed as a sorted set of post_ids
- -Post Cache (Redis): caches hot post objects to avoid DB reads on every feed request
- -Ranking Service: scores posts using engagement signals, recency, and user affinity
Detailed Component Design
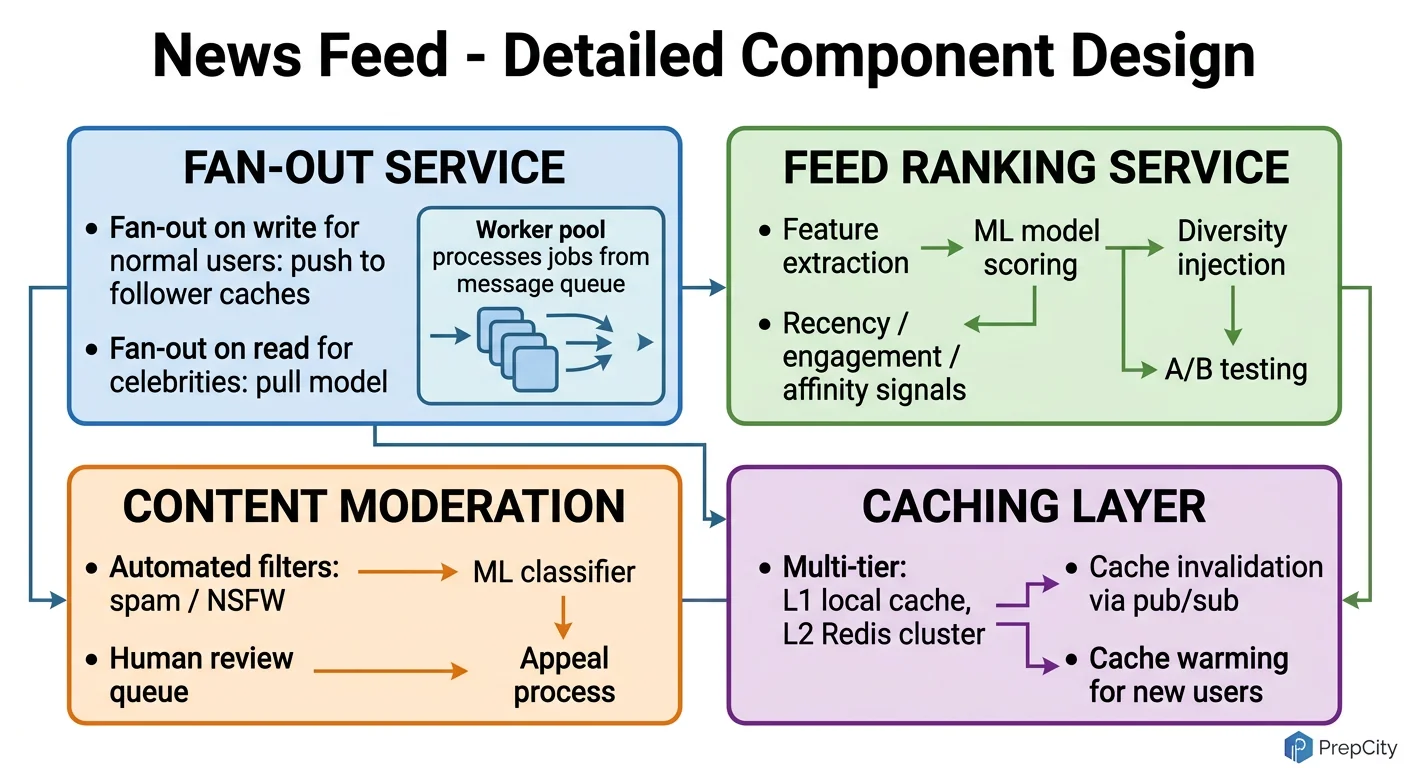
Detailed Component Design
Three components deserve a deep look: the Fan-out Service, the Feed Cache, and the Ranking Service.
Fan-out Service
- -This is the most write-intensive component. When a user with 1M followers posts, the fan-out service must append a post_id to 1M Redis sorted sets.
- -Use Kafka with partitioning by author_id. Each partition is consumed by a worker pool. Workers batch Redis ZADD operations (pipeline 1000 writes at a time) to maximize throughput.
- -Celebrity optimization: users with >100K followers get flagged as "high-fanout." Their posts are NOT fanned out at write time. Instead, their posts are merged at read time (hybrid approach). This prevents a single post from creating millions of writes.
- -Why Kafka over RabbitMQ: Kafka handles replay (if a worker crashes, it re-reads from the offset), has higher throughput for this bursty workload, and partitioning aligns naturally with user-based sharding.
Feed Cache (Redis)
- -Each user's feed is a Redis sorted set: key =
feed:{user_id}, members = post_ids, scores = timestamps. - -Cap each feed at 800 entries using ZREMRANGEBYRANK - nobody scrolls past 800 posts.
- -Memory math: 800 entries * 16 bytes (8-byte post_id + 8-byte score) = 12.8KB per user. At 500M users, that's 6.4TB. With Redis cluster overhead, plan for ~10TB across 20 nodes.
- -Why sorted sets over lists: sorted sets give O(log N) insertion and range queries, and naturally deduplicate. Lists require manual dedup and don't support efficient range queries by score.
Ranking Service
- -Ranking happens at read time, after retrieving candidate post_ids from the feed cache.
- -Feature vector per post: recency, author affinity (how often this user engages with the author), engagement velocity (likes/comments in first hour), content type preference.
- -Use a lightweight ML model (gradient-boosted trees, not a transformer) for sub-10ms inference. Pre-compute author affinity scores in a batch job and store them in a feature store.
- -Why not rank at write time: user preferences change, engagement signals evolve. Ranking at read time uses the freshest signals.
Data Model & Database Design
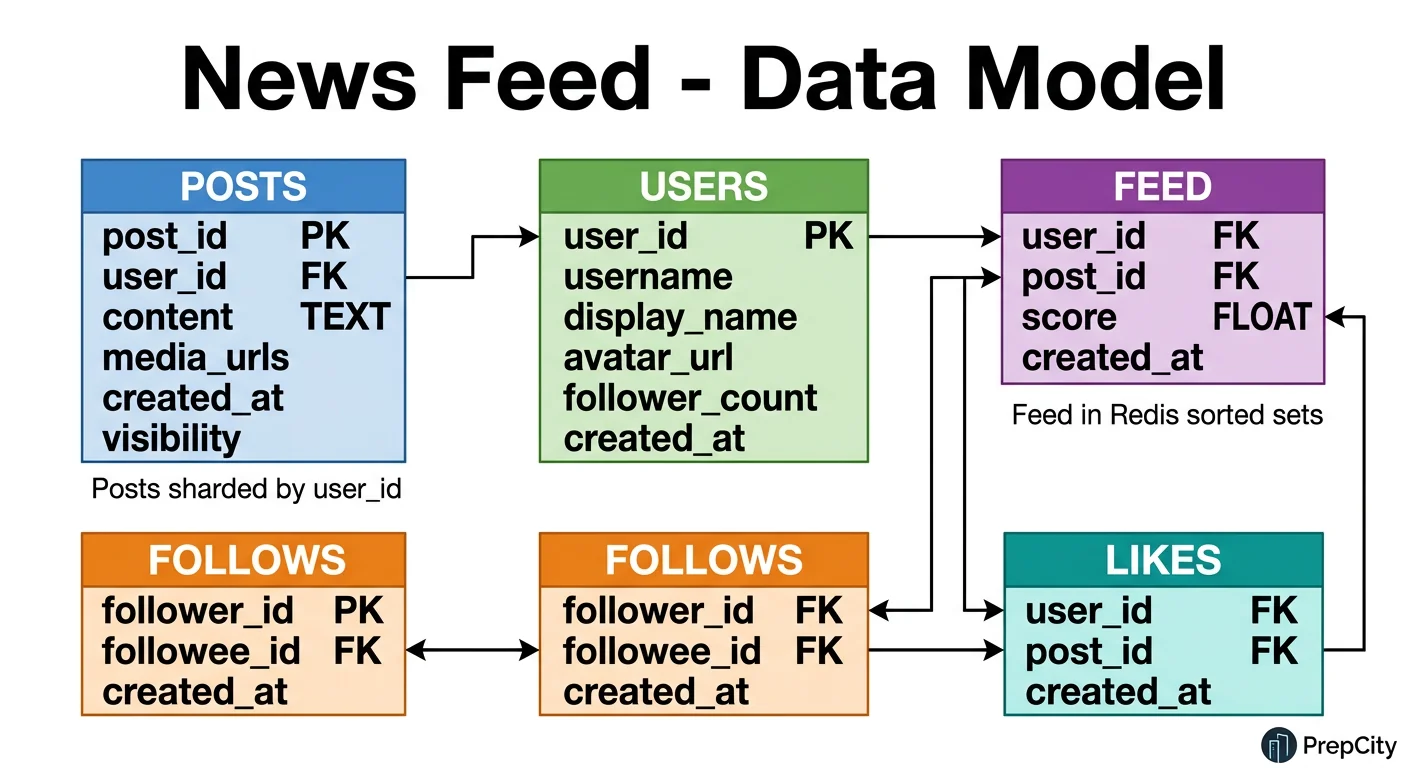
Data Model & Database Design
Hybrid storage: PostgreSQL for structured data, Redis for feed cache, S3 for media.
PostgreSQL Tables (sharded by user_id)
```sql
- -- Posts table: the source of truth
- -CREATE TABLE posts (
- -post_id BIGINT PRIMARY KEY, -- Snowflake ID (time-sortable)
- -user_id BIGINT NOT NULL,
- -content TEXT,
- -media_urls JSONB,
- -created_at TIMESTAMPTZ DEFAULT NOW()
- -);
- -CREATE INDEX idx_posts_user_time ON posts (user_id, created_at DESC);
- -- Follow relationships
- -CREATE TABLE follows (
- -follower_id BIGINT NOT NULL,
- -followee_id BIGINT NOT NULL,
- -created_at TIMESTAMPTZ DEFAULT NOW(),
- -PRIMARY KEY (follower_id, followee_id)
- -);
- -CREATE INDEX idx_follows_followee ON follows (followee_id);
- -- Engagement counts (denormalized for read performance)
- -CREATE TABLE post_stats (
- -post_id BIGINT PRIMARY KEY,
- -likes_count INT DEFAULT 0,
- -comments_count INT DEFAULT 0
- -);
- -
`
Why Snowflake IDs: they're time-sortable (no need for a separate created_at index for ordering), globally unique without coordination, and 8 bytes vs 16 bytes for UUIDs.
Sharding strategy
- -Posts table: shard by user_id. All posts from one user live on the same shard, making author-page queries fast.
- -Follows table: shard by follower_id. Feed generation needs "who does user X follow?" which hits a single shard.
- -For "who follows user X?" (needed by fan-out), maintain a reverse index sharded by followee_id on a separate cluster.
Redis Feed Structure
- -Key:
feed:{user_id}, Type: Sorted Set - -Score: post timestamp (Unix ms), Member: post_id
- -TTL: 7 days for inactive users, no TTL for active users
Post cache (Redis)
- -Key:
post:{post_id}, Type: Hash - -Fields: user_id, content, media_urls, likes_count, comments_count
- -TTL: 24 hours, refreshed on access
Deep Dives
Deep Dives
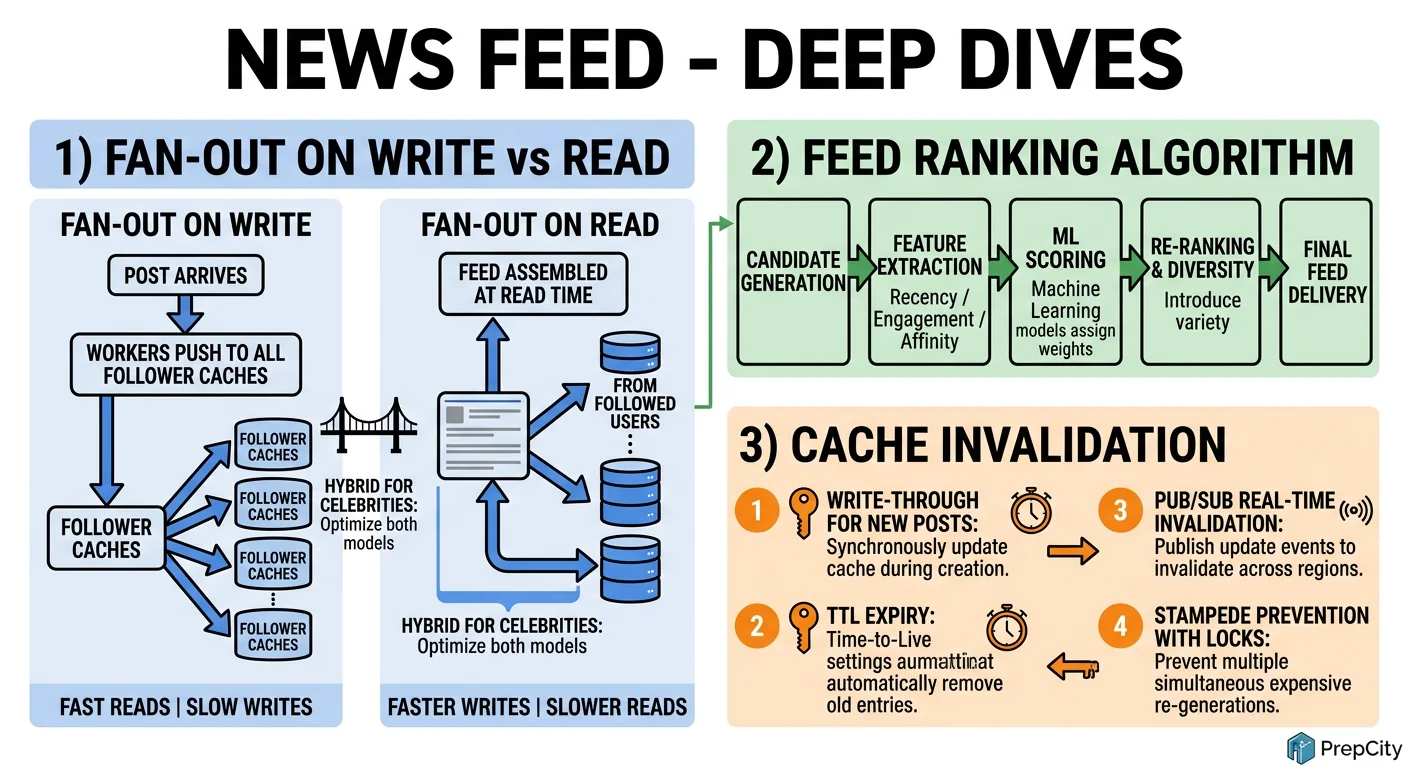
Deep Dive 1: Fan-Out Strategy - Push vs Pull vs Hybrid
The problem: When a user posts, how do you get that post into every follower's feed? The answer depends on the follower count.
- -Fan-out on write (push): immediately push the post_id into every follower's feed cache. Great for users with <10K followers - low read latency because the feed is pre-computed. The downside: a user with 10M followers generates 10M Redis writes per post. That's a write amplification bomb.
- -Fan-out on read (pull): do nothing at write time. When a user opens their feed, query the posts table for recent posts from everyone they follow, then merge and rank. Eliminates write amplification but shifts cost to the read path - fetching and merging posts from 200 followees per request is expensive at 1.7M QPS.
- -Hybrid (the answer): push for normal users (<100K followers), pull for celebrities. At read time, the Feed Service merges the pre-computed feed from Redis with a real-time query for celebrity posts. This bounds write amplification while keeping read latency low.
The tradeoff: hybrid adds complexity. You need a "celebrity" flag, a separate read-time merge step, and careful tuning of the follower threshold. But it's the only approach that works at Twitter/Facebook scale.
Deep Dive 2: Feed Ranking and Freshness
The problem: chronological feeds are simple but produce poor engagement. Users miss important posts because they're buried under noise. But ranked feeds can feel stale if you over-optimize for engagement.
- -Approach: two-pass ranking. First pass retrieves 500 candidate post_ids from the feed cache. Second pass scores each candidate using a lightweight ML model with features: recency (exponential decay), author affinity (precomputed from interaction history), engagement velocity (likes in first 30 min), and content-type preference.
- -Freshness guarantee: always inject the top 3 most recent posts from close friends into the first page, regardless of ranking score. This prevents the "I posted 5 minutes ago and my friend can't see it" problem.
- -Ranking latency budget: 10ms for scoring 500 posts. Use precomputed feature vectors stored in Redis. The model itself is a gradient-boosted tree served from memory - no network calls during scoring.
The tradeoff: ranked feeds increase engagement 20-30% but generate user complaints about "missing" posts. Provide a "Recent" toggle that switches to chronological ordering.
Deep Dive 3: Cache Invalidation and Consistency
The problem: the feed cache can go stale in multiple ways - a user unfollows someone (stale posts remain), a post is deleted (ghost entries), or engagement counts drift.
- -Unfollow: when user A unfollows user B, enqueue an async job that scans A's feed cache and removes all post_ids authored by B. Use ZRANGEBYSCORE to find them efficiently if you store author_id in a secondary index, or accept eventual cleanup on next feed rebuild.
- -Post deletion: publish a PostDeleted event to Kafka. Fan-out workers remove the post_id from all feeds that contain it. For celebrities (pull model), deletion is instant since there's no cached copy - the post simply won't appear in the next read-time merge.
- -Engagement count drift: post_stats in PostgreSQL is the source of truth. The Redis post cache uses a 60-second TTL on engagement fields. For viral posts (>1000 likes/min), switch to a write-through pattern that updates Redis on every like.
- -Full feed rebuild: run a daily background job that rebuilds feed caches for users who haven't been active in 24+ hours. This corrects any accumulated drift without impacting active users.
Trade-offs & Interview Tips
Key Trade-offs:
- -Push vs Pull vs Hybrid: Pure push doesn't scale for celebrities. Pure pull is too slow at read time. The hybrid approach is more complex to build but is the only realistic option at 500M DAU. In an interview, state the hybrid approach upfront - it shows you understand the problem deeply.
- -SQL vs NoSQL for posts: PostgreSQL with sharding handles the relational queries ("all posts by user X") well and gives ACID guarantees. Cassandra would give better write throughput but makes cross-user queries painful. For a feed system where most queries are single-user, sharded PostgreSQL wins.
- -Ranking at read time vs write time: Read-time ranking uses fresher signals but adds latency. Write-time ranking is stale by the time the user opens the app. Read-time is the right call - budget 10ms for it and precompute features.
- -Eventual consistency on engagement counts: Nobody cares if a like count is off by 2 for 30 seconds. Accepting eventual consistency here avoids expensive distributed transactions and lets you batch counter updates.
What I'd do differently at larger scale
- -Move from PostgreSQL to a purpose-built timeline store (like Twitter's Manhattan) once sharded Postgres management becomes a full-time job
- -Add a "warm-up" service that pre-builds feeds for users predicted to open the app soon (based on usage patterns)
Interview tips
- -Open with the fan-out problem. It's the core challenge - everything else is secondary.
- -Draw the write path and read path separately. Interviewers love seeing you decompose the problem.
- -Mention the celebrity problem before the interviewer asks. It shows depth.
- -Have concrete numbers ready: "500M users * 200 follows = 100B edges in the social graph" demonstrates you can reason about scale.
- -Don't over-design the ranking model. Say "gradient-boosted trees with 4-5 features" and move on. The interviewer wants system design, not ML.
- -Common mistake: forgetting that the follows table needs to be queried in both directions (who do I follow? who follows me?) - this requires two separate indexes or a reverse index.
Ready to be interviewed on this?
Our AI interviewer will test your understanding with follow-up questions
Start Mock Interview