Design a Rate Limiter
A rate limiter is the bouncer at the door of every production API. The real challenge isn't the algorithm - it's making it work across a distributed fleet of servers with sub-5ms latency and graceful failure modes. This walkthrough covers token bucket vs sliding window, Redis-based distributed counting, Lua scripts for atomicity, and the fail-open vs fail-closed decision.
Practice this design with AI
Get coached through each section in a mock interview setting
Problem Statement & Requirements
A rate limiter answers one question: should this request be allowed or rejected? The answer must come in under 5ms, be consistent across a distributed fleet, and handle 50K QPS without becoming the bottleneck it's supposed to prevent.
Functional Requirements
- -Limit requests per client (identified by API key or user ID) within a configurable time window
- -Support different limits per endpoint and per tier (free: 100 req/min, pro: 1000 req/min)
- -Return 429 Too Many Requests with Retry-After header when limit is exceeded
- -Expose rate limit state in response headers: X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset
- -Support both per-user and per-endpoint global limits (e.g., max 10K req/sec to /api/search regardless of user)
- -Admin API for updating rate limit rules without redeployment
Non-Functional Requirements
- -10M DAU, peak 50K QPS across all endpoints
- -p99 decision latency < 5ms (the rate limiter cannot add meaningful latency to every request)
- -99.99% availability - if the rate limiter goes down, it should fail open, not take down the API
- -Accurate within 1% - small overcounting is acceptable, undercounting is not
- -Rules stored durably; counters are ephemeral (losing a few seconds of counter state on failure is fine)
Out of Scope
- -DDoS mitigation (that's L3/L4, handled by CDN/WAF)
- -Dynamic rate limiting based on server load (interesting but a separate system)
- -User authentication (assume the API gateway has already resolved the API key to a user ID)
Back-of-Envelope Estimation
The rate limiter sits in the hot path of every API request, so resource usage scales with total QPS, not with data volume.
QPS
- -10M DAU * ~10 requests/day avg = 100M requests/day
- -Average QPS: 100M / 86,400 = ~1,150 req/sec
- -Peak QPS (3x): ~3,500 req/sec
- -Design target: 50K QPS (10x headroom for growth and spikes)
Redis memory per counter
- -Token bucket: 2 fields per key (tokens remaining + last refill timestamp) = ~20 bytes per key
- -Active users at any moment: ~10% of DAU = 1M concurrent users
- -Memory for user counters: 1M * 20 bytes = 20MB
- -With per-endpoint limits (assume 5 endpoints): 100MB
- -This is tiny. A single Redis node with 1GB handles this with room to spare.
Redis operations
- -Each rate limit check = 1 Lua script execution (GET + conditional SET + EXPIRE)
- -At 50K QPS, Redis handles this easily - a single Redis node does 100K+ ops/sec
- -Use a Redis cluster (3 masters + 3 replicas) for availability, not for capacity
Network bandwidth
- -Request to Redis: ~100 bytes (key + Lua script args)
- -Response from Redis: ~50 bytes (allowed/denied + remaining count)
- -At 50K QPS: 50K * 150 bytes = 7.5 MB/sec - negligible
Rule storage
- -Rate limit rules (tier definitions, per-endpoint configs): maybe 1000 rules
- -Store in PostgreSQL, cache in Redis with 60-second TTL
- -Memory: < 1MB
Bottom line: the rate limiter is CPU and latency bound, not memory or storage bound.
API Design
The rate limiter is not a user-facing API. It's middleware that intercepts every request. But it does need an admin API for rule management.
Rate Limit Headers (added to every API response)
X-RateLimit-Limit: 100 X-RateLimit-Remaining: 73 X-RateLimit-Reset: 1710680400 Retry-After: 12 (only on 429 responses)
Internal Rate Check (called by API gateway middleware)
- -POST
/internal/rate-check - -Request:
- -```json
- -
` - -Response (200 = allowed):
- -```json
- -
` - -Response (200, but request should be rejected):
- -```json
- -
`
Admin API - Update Rule
- -PUT
/admin/v1/rules/{rule_id} - -Request:
- -```json
- -
` - -Response (200):
- -```json
- -
`
Note: the internal rate-check endpoint returns 200 even for denied requests. The API gateway reads the allowed field and decides whether to return 429 to the client. This keeps the rate limiter decoupled from HTTP semantics.
High-Level Architecture
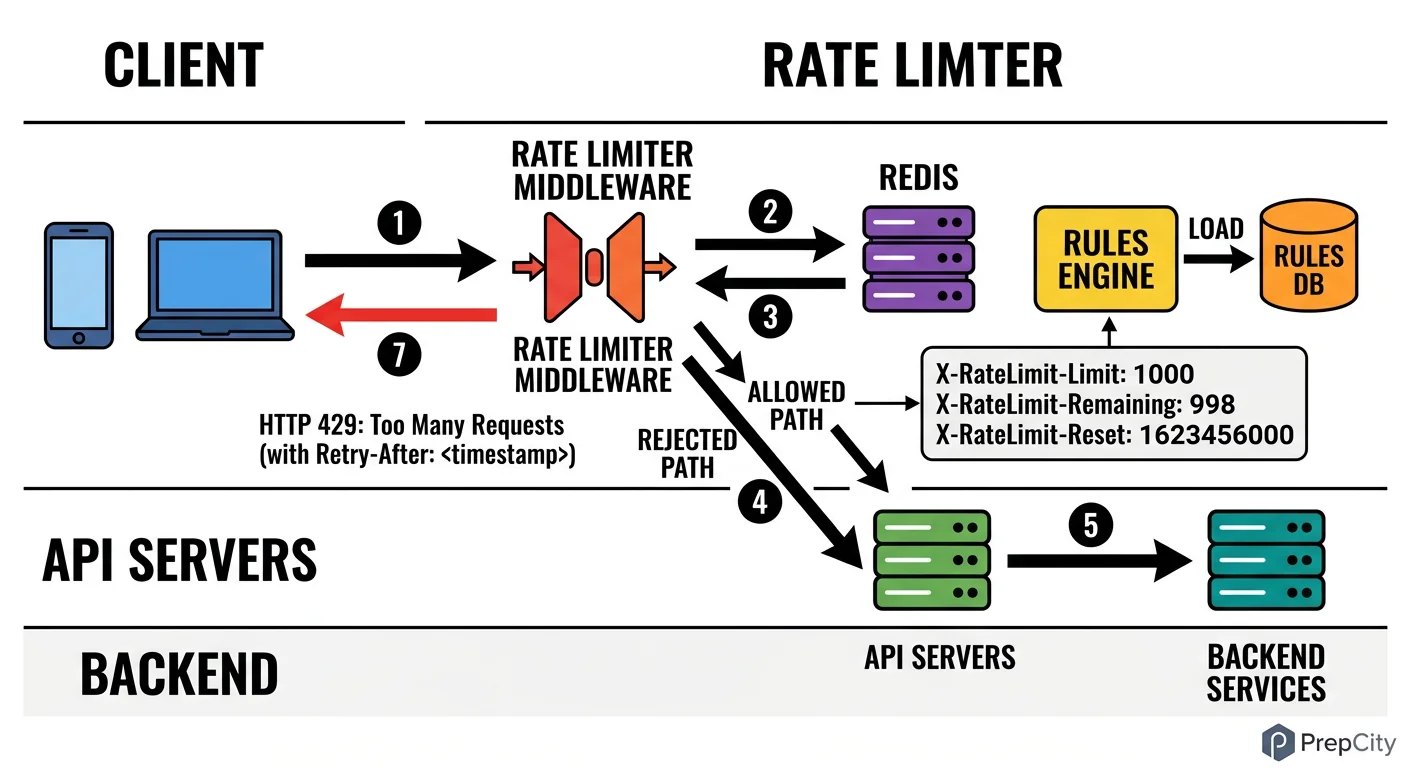
High-Level Architecture
The rate limiter is embedded in the API gateway layer, not a standalone service that every request hops through. This is critical for latency - adding a network hop for every request would blow the 5ms budget.
Request flow
1. Client sends a request to the API gateway (Nginx/Envoy/Kong) 2. The gateway's rate limit middleware extracts the client_id and endpoint from the request 3. Middleware executes a Lua script on Redis that atomically checks and updates the counter 4. If allowed: request passes through to the backend service. Rate limit headers are added to the response. 5. If denied: gateway returns 429 immediately with Retry-After header. Request never reaches the backend.
Components
- -API Gateway (Envoy/Kong): runs the rate limit middleware as a plugin. Each gateway instance connects to the Redis cluster directly.
- -Redis Cluster (3 masters + 3 replicas): stores rate limit counters. Masters are sharded by client_id using consistent hashing. Replicas provide failover.
- -Rules Service (lightweight): exposes the admin API for CRUD on rate limit rules. Writes rules to PostgreSQL and invalidates the Redis rule cache.
- -PostgreSQL: durable storage for rate limit rules and tier definitions. Not in the hot path - rules are cached in Redis.
- -Monitoring (Prometheus + Grafana): the gateway emits metrics on every rate limit decision (allowed/denied, latency, Redis errors).
Why not a separate rate limiter service
- -A separate service adds 1-3ms of network latency per request. At 50K QPS, that's an unacceptable tax.
- -Embedding the logic in the gateway means the check is a single Redis round-trip (~1ms) plus local computation (~0.1ms).
- -The downside of embedding: you need to deploy rate limit logic changes to every gateway instance. Mitigate this by keeping the logic simple (Lua scripts in Redis) and configurable via rules.
Detailed Component Design
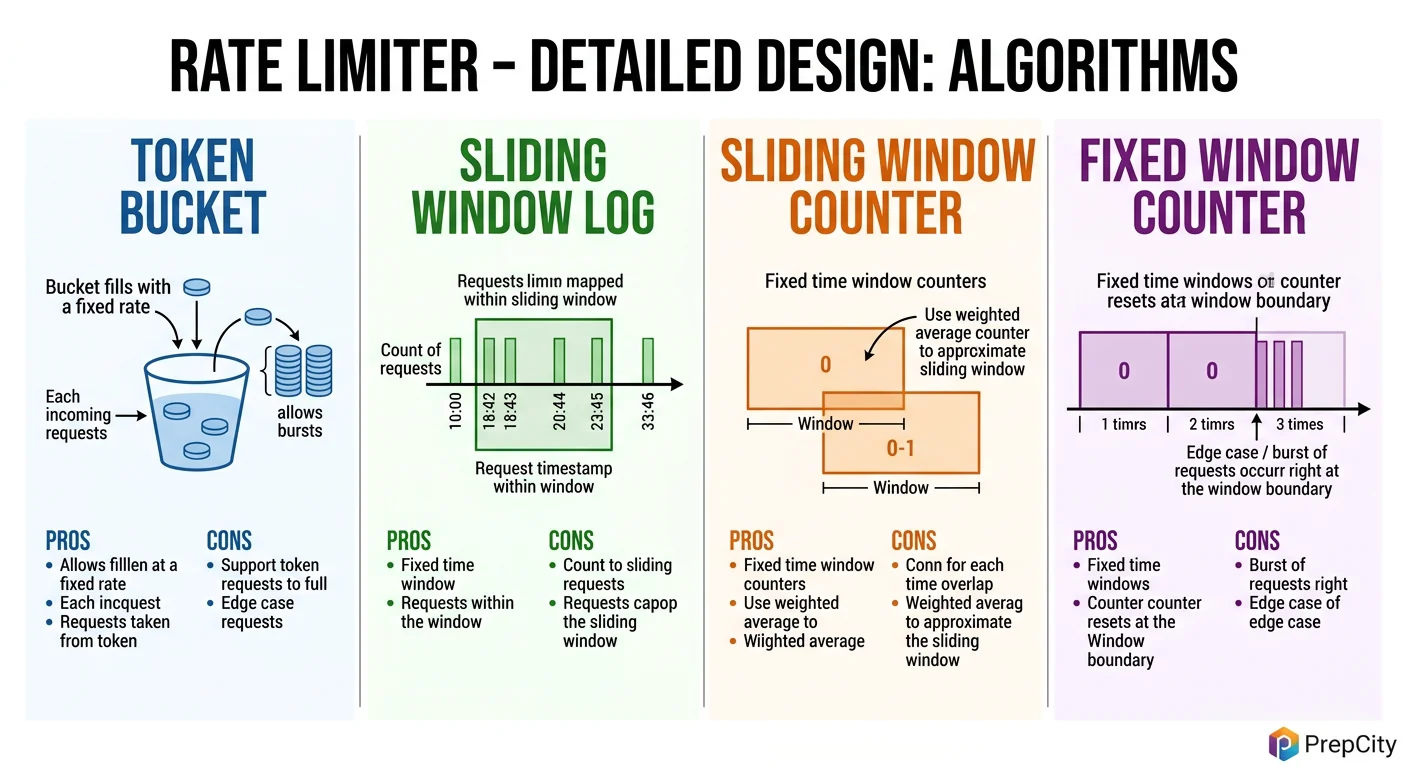
Detailed Component Design
Two components need detailed treatment: the rate limiting algorithm and the Redis Lua script that implements it.
Algorithm: Sliding Window Counter (not Token Bucket)
Token bucket is the textbook answer, but sliding window counter is what you should actually use. Here's why:
- -Token bucket allows bursts up to the bucket size. If the limit is 100 req/min with a full bucket, a client can fire 100 requests in the first second. That burst can overwhelm downstream services.
- -Sliding window counter smooths traffic by counting requests in the current window and weighting the previous window. No bursts larger than the configured rate.
- -Implementation: maintain two counters in Redis - current window and previous window. The effective count = (previous_count * overlap_percentage) + current_count. If effective count >= limit, reject.
Example: limit is 100 req/min. At 15 seconds into the current minute, previous window had 80 requests, current window has 30.
- -Overlap of previous window: (60 - 15) / 60 = 75%
- -Effective count: 80 * 0.75 + 30 = 90. Under 100, so allowed.
Why not fixed window: a client can send 100 requests at 11:00:59 and 100 more at 11:01:00, effectively getting 200 req/min. The sliding window eliminates this boundary problem.
Redis Lua Script
The entire rate limit check must be atomic. If you do GET then SET as separate Redis commands, two concurrent requests can both read "99 remaining" and both think they're allowed. Lua scripts execute atomically on a single Redis node.
```lua local key_prev = KEYS[1] local key_curr = KEYS[2] local limit = tonumber(ARGV[1]) local window = tonumber(ARGV[2]) local now = tonumber(ARGV[3])
local prev_count = tonumber(redis.call('GET', key_prev) or '0') local curr_count = tonumber(redis.call('GET', key_curr) or '0') local elapsed = now % window local weight = (window - elapsed) / window local effective = math.floor(prev_count * weight) + curr_count
if effective >= limit then return {0, limit - effective, window - elapsed} end
redis.call('INCR', key_curr) redis.call('EXPIRE', key_curr, window * 2) return {1, limit - effective - 1, window - elapsed} ```
Returns: {allowed (0/1), remaining, seconds until reset}. The gateway reads these three values and populates the response headers.
Rule Resolution
- -Rules are stored in PostgreSQL with columns: endpoint, tier, limit, window_seconds
- -Cached in Redis as a hash:
rules:{endpoint}:{tier}with 60-second TTL - -On rule update, the Rules Service publishes an invalidation message to a Redis pub/sub channel. All gateway instances subscribe and evict the stale rule from local cache.
Data Model & Database Design
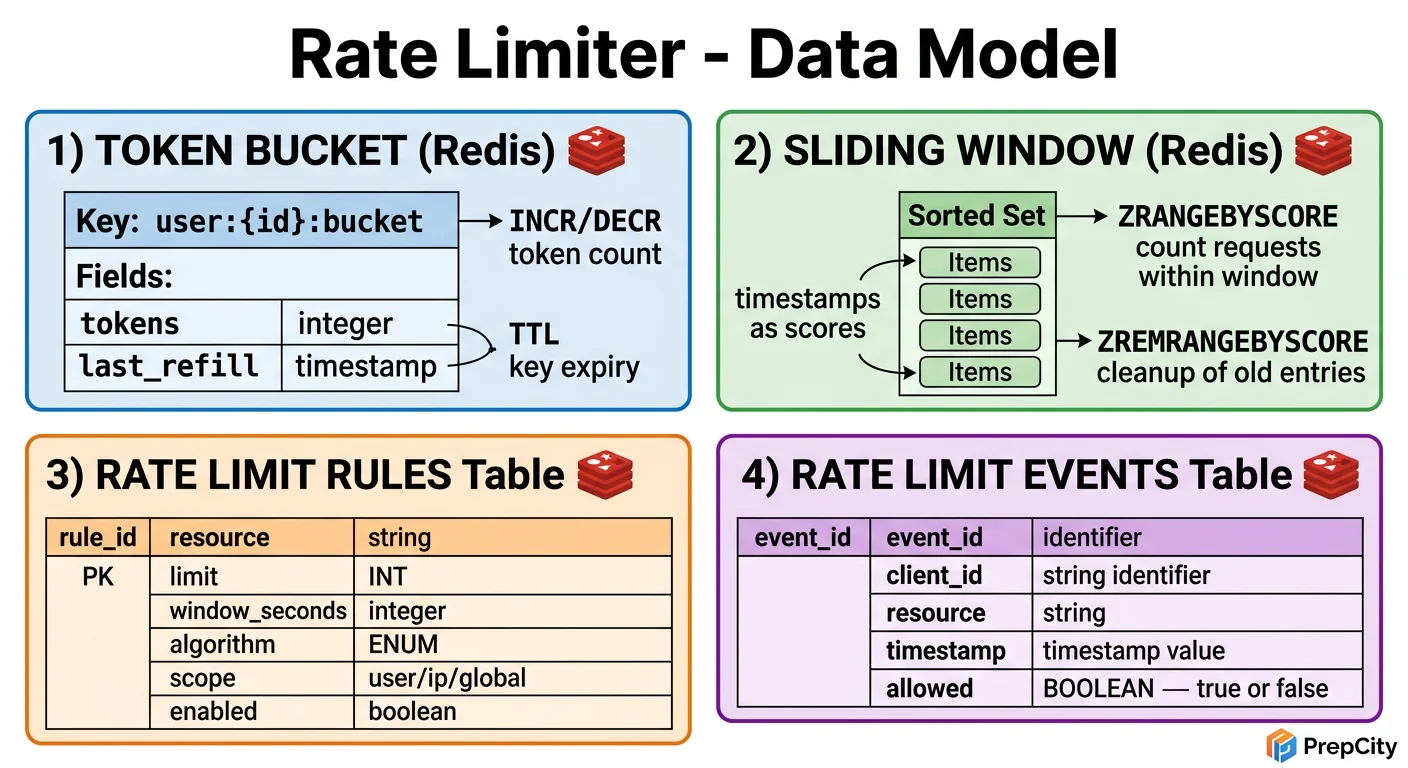
Data Model & Database Design
Two storage layers: PostgreSQL for durable rule configuration, Redis for ephemeral counters.
PostgreSQL (rule storage)
```sql CREATE TABLE rate_limit_rules ( id SERIAL PRIMARY KEY, endpoint VARCHAR(255) NOT NULL, tier VARCHAR(50) NOT NULL DEFAULT 'default', limit_count INT NOT NULL, window_secs INT NOT NULL, created_at TIMESTAMPTZ DEFAULT NOW(), updated_at TIMESTAMPTZ DEFAULT NOW(), UNIQUE (endpoint, tier) );
CREATE TABLE api_keys ( api_key VARCHAR(64) PRIMARY KEY, user_id BIGINT NOT NULL, tier VARCHAR(50) NOT NULL DEFAULT 'free', enabled BOOLEAN DEFAULT TRUE, created_at TIMESTAMPTZ DEFAULT NOW() ); CREATE INDEX idx_apikeys_user ON api_keys (user_id); ```
The UNIQUE constraint on (endpoint, tier) ensures one rule per endpoint-tier combination. No ambiguity in rule resolution.
Redis (counter storage)
Key pattern: rl:{client_id}:{endpoint}:{window_start}
- -Example:
rl:user_abc:/api/v1/posts:1710680400 - -Value: integer counter
- -TTL: 2 * window_seconds (keep previous window for sliding window calculation)
Two keys exist per client-endpoint pair at any time: the current window and the previous window. Once the previous window's TTL expires, Redis evicts it automatically. No cleanup jobs needed.
Why not a Redis sorted set (the "sliding window log" approach)
- -Sorted sets store every request timestamp. At 1000 req/min, that's 1000 entries per user per endpoint.
- -ZRANGEBYSCORE to count entries in the window is O(log N + M) per check.
- -The counter approach uses O(1) space and O(1) operations. At 50K QPS, this difference matters.
Rule cache in Redis
- -Key:
rules:{endpoint}:{tier} - -Value: JSON
{"limit": 1000, "window_secs": 60} - -TTL: 60 seconds
No sharding needed for rules (< 1MB total). Counter keys are automatically distributed across Redis cluster masters by consistent hashing on the key.
Deep Dives
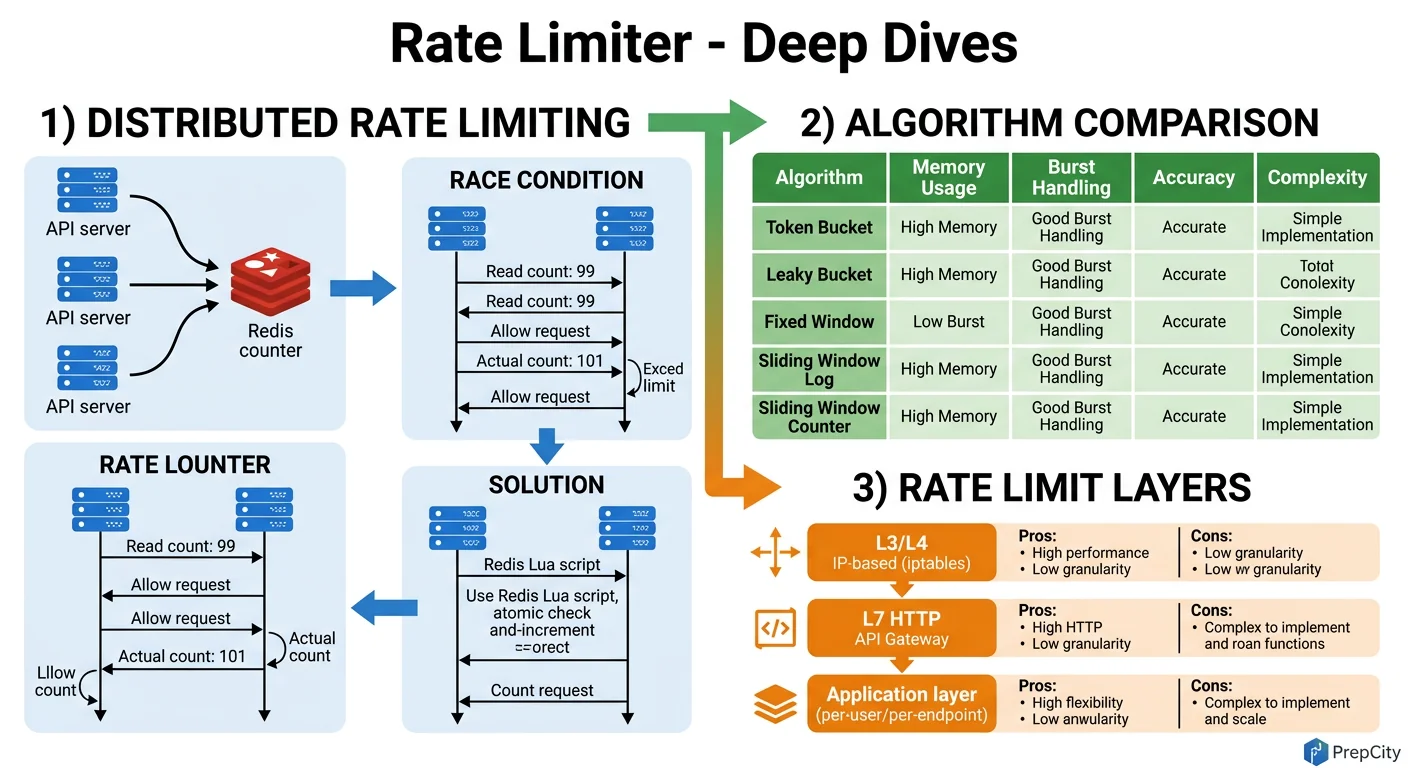
Deep Dives
Deep Dive 1: Distributed Consistency - Race Conditions Across Gateway Instances
The problem: 10 API gateway instances all talk to the same Redis cluster. Two requests from the same client hit different gateways simultaneously. Both execute the Lua script. Is the count accurate?
Yes - because Redis executes Lua scripts atomically on a single thread. Both requests hash to the same Redis master (same client_id in the key), and Redis serializes the script executions. No race condition.
But what if the Redis cluster uses multiple masters? The client_id-based key ensures both requests route to the same master via consistent hashing. The only risk is during a Redis cluster rebalancing (slot migration), where a brief window of inconsistency can allow 1-2 extra requests through. This is within the 1% accuracy tolerance.
For global per-endpoint limits (e.g., 10K req/sec to /api/search across all users), the counter key doesn't include client_id. All gateways hit the same Redis key on the same master. At 50K QPS to a single key, Redis handles it fine - single-key operations are its sweet spot.
Deep Dive 2: Fail-Open vs Fail-Closed
The problem: Redis goes down. Every request now can't be rate-checked. What do you do?
- -Fail-open: allow all requests through. The API stays up, but you lose rate limiting protection. A misbehaving client could hammer your backend.
- -Fail-closed: reject all requests. Your API goes down entirely. No one can use it.
- -The right answer is fail-open with local fallback. Each gateway instance maintains an in-memory token bucket as a fallback. When Redis is unreachable, the gateway switches to local rate limiting. It's not globally consistent (each gateway enforces independently), but it provides rough protection. The effective limit becomes N * per-gateway-limit where N is the number of gateways, so set the local limit to global_limit / num_gateways.
Detection: use a circuit breaker pattern. After 3 consecutive Redis failures within 1 second, trip the circuit and switch to local mode. After 10 seconds, try one Redis call (half-open). If it succeeds, resume normal mode.
Deep Dive 3: Hot Key Problem at Scale
The problem: a single API key making millions of requests per second. The Redis key for that client becomes a hot key on one master node, causing latency spikes.
- -Approach 1: client-side rate limiting in the gateway. Before even hitting Redis, check a local counter. If the client has already sent 10x their limit in the last second, reject locally. This absorbs the blast radius.
- -Approach 2: key splitting. Instead of one key
rl:user_abc:/api/search:17106804, split intorl:user_abc:/api/search:17106804:shard_0throughshard_4. Each gateway picks a shard randomly, INCRs it, and the Lua script sums all shards. Spreads load across Redis masters at the cost of slightly less accurate counting.
In practice, combine both: local pre-filtering catches obvious abusers, key splitting handles the gray zone.
Trade-offs & Interview Tips
Key Trade-offs:
- -Sliding window counter vs token bucket: Sliding window prevents bursts and eliminates boundary problems. Token bucket is simpler and allows controlled bursts. Use sliding window for API rate limiting (you want smooth traffic); use token bucket for scenarios where bursts are acceptable (like network traffic shaping).
- -Embedded middleware vs standalone service: Embedding in the gateway saves 1-3ms per request but couples deployment. A standalone service is cleaner architecturally but adds latency. At 50K QPS, latency wins - embed it.
- -Redis vs in-memory only: Redis gives global consistency across gateway instances. In-memory is faster but each gateway counts independently, so a client can get N * limit by hitting different gateways. Redis is the right choice unless you're okay with approximate limiting.
- -Fail-open vs fail-closed: Fail-open with local fallback is the pragmatic choice. Pure fail-closed is only appropriate for payment APIs or security-critical endpoints where letting bad traffic through is worse than downtime.
What I'd change at 10x scale
- -Add a local cache layer (in-memory LRU) that absorbs repeated checks for the same client within 100ms. Most clients send requests in bursts - caching the "allowed" result for 100ms reduces Redis load by 50-70%.
- -Move from Redis Cluster to DragonflyDB for higher single-node throughput and lower tail latency.
Interview tips
- -Start with the algorithm comparison. Draw token bucket, fixed window, and sliding window on the whiteboard. Explain the boundary problem with fixed window - this is the key insight interviewers look for.
- -Mention Lua scripts early. Atomicity in Redis is the make-or-break detail. If you don't mention it, the interviewer will ask "what about race conditions?" and you'll be on the back foot.
- -Discuss fail-open vs fail-closed without being asked. It shows operational maturity.
- -Don't forget the response headers. X-RateLimit-Remaining is how clients self-regulate. Without it, they have to guess and will over-request.
- -Common mistake: designing a separate rate limiter service that every request calls over the network. This doubles your latency and creates a single point of failure. Embed the logic in the gateway.
- -Common mistake: using sorted sets for sliding window log at scale. It works for small traffic but the memory and CPU cost grows linearly with request volume. Counters are O(1).
Previous
Design a News Feed (Twitter / Facebook)
Next
Design a Video Streaming Platform (YouTube / Netflix)
Ready to be interviewed on this?
Our AI interviewer will test your understanding with follow-up questions
Start Mock Interview